


بهروزرسانی ساعت ۲:۴۰ بعدازظهر به وقت اقیانوس آرام: چند ساعت پس از انتشار GPT-4.5، اوپنایآی جملهای را از مقاله سفید این مدل هوش مصنوعی حذف کرد که بیان میداشت «GPT-4.5 یک مدل پیشگام هوش مصنوعی نیست.» مقاله سفید جدید GPT-4.5 دیگر شامل این جمله نیست. میتوانید لینک مقاله سفید قدیمی را اینجا بیابید. مقاله اصلی در ادامه آمده است.
OpenAI روز پنجشنبه اعلام کرد که GPT-4.5، مدل هوش مصنوعی مورد انتظار با اسم رمز اوریون (Orion)، را عرضه میکند. GPT-4.5 بزرگترین مدل OpenAI تا به امروز است که با استفاده از قدرت محاسباتی و دادههای بیشتری نسبت به هر یک از نسخههای قبلی این شرکت آموزش دیده است.
با وجود اندازه بزرگ آن، OpenAI در مقاله سفید خود اشاره میکند که GPT-4.5 را یک مدل پیشگام (frontier) نمیداند.
مشترکان طرح ChatGPT Pro، که برنامهای با هزینه ۲۰۰ دلار در ماه است، از روز پنجشنبه بهعنوان بخشی از پیشنمایش پژوهشی در ChatGPT به GPT-4.5 دسترسی خواهند داشت. توسعهدهندگان در سطوح پولی API OpenAI نیز از امروز میتوانند از GPT-4.5 استفاده کنند. سخنگوی OpenAI به تککرانچ گفت که برای دیگر کاربران ChatGPT، مشتریان ثبتنامشده در ChatGPT Plus و ChatGPT Team باید هفته آینده به این مدل دسترسی پیدا کنند.
صنعت با نفس حبسشده منتظر اوریون بوده است، که برخی آن را شاخصی برای پایداری رویکردهای سنتی آموزش هوش مصنوعی میدانند. GPT-4.5 با استفاده از همان تکنیک کلیدی توسعه یافته است — افزایش چشمگیر قدرت محاسباتی و دادهها در مرحله «پیشآموزش» که یادگیری بدون نظارت نامیده میشود — که OpenAI برای توسعه GPT-4، GPT-3، GPT-2 و GPT-1 به کار برده بود.
در هر نسل از GPT پیش از GPT-4.5، افزایش مقیاس به جهشهای عظیمی در عملکرد در حوزههای مختلف، از جمله ریاضیات، نگارش و کدنویسی منجر شده بود. در واقع، OpenAI اعلام کرده که اندازه بزرگتر GPT-4.5 به آن «دانش جهانی عمیقتر» و «هوش عاطفی بالاتر» بخشیده است. با این حال، نشانههایی وجود دارد که نشان میدهد دستاوردهای ناشی از افزایش مقیاس دادهها و محاسبات در حال کاهش است. در چندین معیار هوش مصنوعی، GPT-4.5 از مدلهای جدیدتر «استدلالی» هوش مصنوعی شرکت چینی DeepSeek، Anthropic و خود OpenAI عقب میماند.
OpenAI اذعان دارد که اجرای GPT-4.5 بسیار پرهزینه است — بهحدی که این شرکت میگوید در حال ارزیابی است که آیا در درازمدت ارائه GPT-4.5 در API خود را ادامه دهد یا خیر. برای دسترسی به API GPT-4.5، OpenAI از توسعهدهندگان ۷۵ دلار به ازای هر میلیون توکن ورودی (تقریباً ۷۵۰,۰۰۰ کلمه) و ۱۵۰ دلار به ازای هر میلیون توکن خروجی دریافت میکند. این در حالی است که GPT-4o تنها ۲.۵۰ دلار به ازای هر میلیون توکن ورودی و ۱۰ دلار به ازای هر میلیون توکن خروجی هزینه دارد.
OpenAI در پستی وبلاگی که با تککرانچ به اشتراک گذاشته شده، اعلام کرد: «ما GPT-4.5 را بهعنوان یک پیشنمایش پژوهشی به اشتراک میگذاریم تا نقاط قوت و محدودیتهای آن را بهتر درک کنیم. هنوز در حال کاوش قابلیتهای آن هستیم و مشتاقیم ببینیم که مردم چگونه از آن به روشهایی که شاید انتظارش را نداشتهایم استفاده میکنند.»
عملکرد ترکیبی
OpenAI تأکید میکند که GPT-4.5 قرار نیست جایگزین مستقیمی برای GPT-4o، مدل کاری اصلی این شرکت که بیشتر API و ChatGPT را پشتیبانی میکند، باشد. در حالی که GPT-4.5 از ویژگیهایی مانند بارگذاری فایل و تصویر و ابزار بوم ChatGPT پشتیبانی میکند، در حال حاضر فاقد قابلیتهایی مانند پشتیبانی از حالت گفتوگوی دوطرفه واقعی ChatGPT است.
در جنبه مثبت، GPT-4.5 از GPT-4o و بسیاری از مدلهای دیگر عملکرد بهتری دارد.
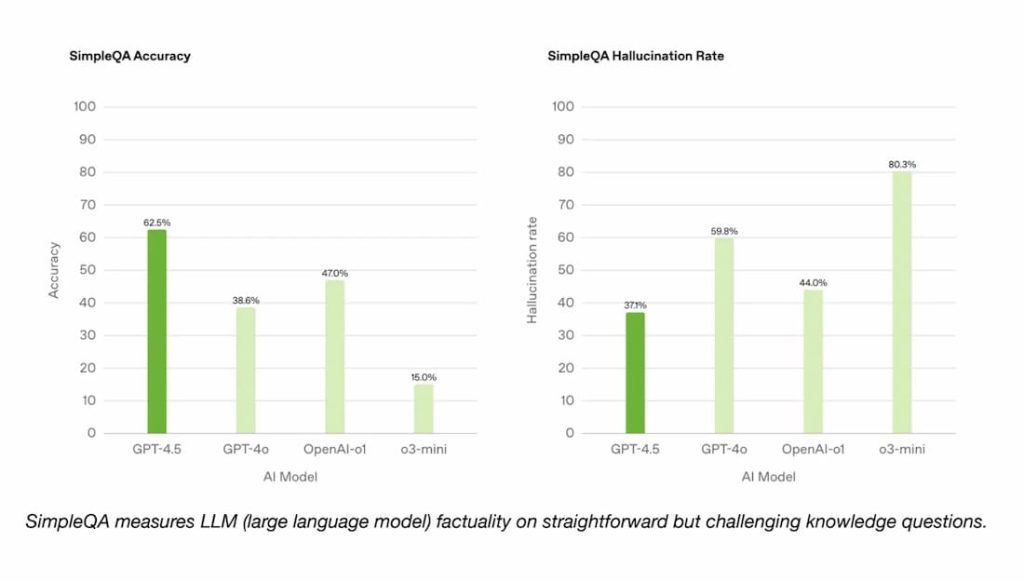
در معیار SimpleQA شرکت OpenAI، که مدلهای هوش مصنوعی را با سؤالات واقعی و ساده آزمایش میکند، GPT-4.5 از نظر دقت از GPT-4o و مدلهای استدلالی OpenAI، یعنی o1 و o3-mini، پیشی میگیرد. به گفته OpenAI، GPT-4.5 نسبت به اکثر مدلها کمتر دچار توهم میشود، که در تئوری یعنی احتمال کمتری دارد که اطلاعات نادرست تولید کند.
OpenAI یکی از برترین مدلهای استدلالی خود، deep research، را در SimpleQA فهرست نکرده است. سخنگوی OpenAI به تککرانچ میگوید که عملکرد deep research در این معیار بهصورت عمومی گزارش نشده و ادعا میکند که مقایسه مرتبطی نیست. با این حال، مدل Deep Research استارتاپ Perplexity، که در سایر معیارها عملکردی مشابه deep research OpenAI دارد، در این آزمون دقت واقعی از GPT-4.5 پیشی میگیرد.
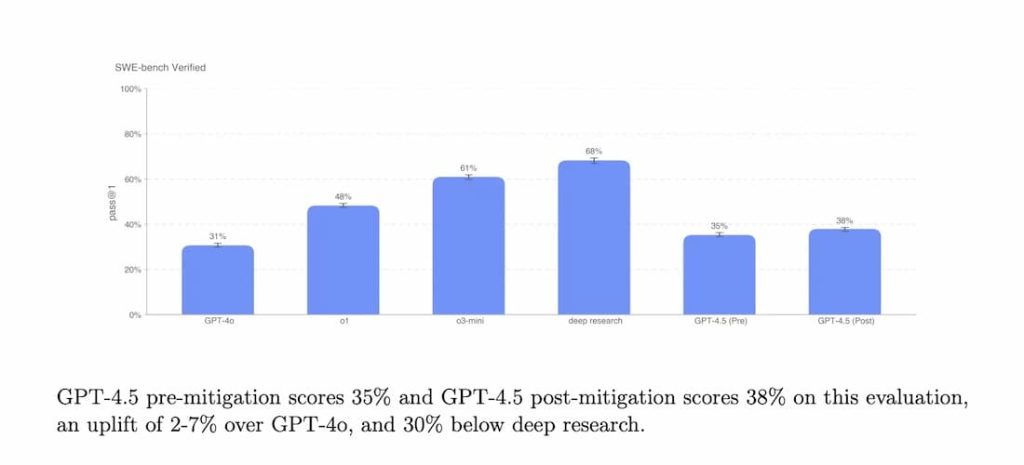
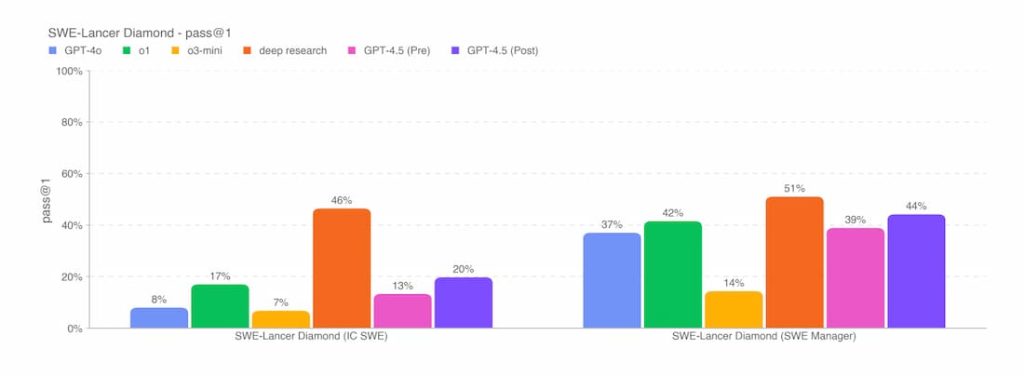
در زیرمجموعهای از مسائل کدنویسی، معیار SWE-Bench Verified، عملکرد GPT-4.5 تقریباً با GPT-4o و o3-mini برابری میکند، اما از deep research شرکت OpenAI و Claude 3.7 Sonnet شرکت Anthropic عقب میماند. در آزمون کدنویسی دیگری، معیار SWE-Lancer شرکت OpenAI، که توانایی یک مدل هوش مصنوعی در توسعه ویژگیهای کامل نرمافزاری را میسنجد، GPT-4.5 از GPT-4o و o3-mini پیشی میگیرد، اما همچنان از deep research عقب است.
GPT-4.5 در معیارهای دشوار دانشگاهی مانند AIME و GPQA به سطح عملکرد برترین مدلهای استدلالی هوش مصنوعی، مانند o3-mini، R1 شرکت DeepSeek و Claude 3.7 Sonnet (که از نظر فنی یک مدل ترکیبی است)، نمیرسد. اما GPT-4.5 در این آزمونها با برترین مدلهای غیراستدلالی برابری میکند یا از آنها پیشی میگیرد، که نشان میدهد این مدل در مسائل مرتبط با ریاضیات و علوم عملکرد خوبی دارد.
OpenAI همچنین ادعا میکند که GPT-4.5 از نظر کیفی در زمینههایی که معیارها بهخوبی آنها را پوشش نمیدهند، مانند توانایی درک نیت انسانی، نسبت به سایر مدلها برتری دارد. به گفته OpenAI، GPT-4.5 با لحنی گرمتر و طبیعیتر پاسخ میدهد و در وظایف خلاقانه مانند نگارش و طراحی عملکرد خوبی از خود نشان میدهد.
در یک آزمایش غیررسمی، OpenAI از GPT-4.5 و دو مدل دیگر، یعنی GPT-4o و o3-mini، خواست تا یک یونیکورن در فرمت SVG، که فرمتی برای نمایش گرافیک بر اساس فرمولهای ریاضی و کد است، ایجاد کنند. GPT-4.5 تنها مدل هوش مصنوعی بود که توانست چیزی شبیه به یونیکورن خلق کند.

در آزمایشی دیگر، OpenAI از GPT-4.5 و دو مدل دیگر خواست تا به درخواست «من پس از شکست در یک آزمون دوران سختی را سپری میکنم» پاسخ دهند. GPT-4o و o3-mini اطلاعات مفیدی ارائه دادند، اما پاسخ GPT-4.5 از نظر اجتماعی مناسبترین بود.
OpenAI در پست وبلاگ خود نوشت: «ما مشتاقیم با این انتشار، تصویر کاملتری از قابلیتهای GPT-4.5 به دست آوریم، زیرا میدانیم معیارهای دانشگاهی همیشه کاربرد واقعی در دنیای واقعی را منعکس نمیکنند.»

قوانین مقیاسپذیری به چالش کشیده شدهاند
OpenAI ادعا میکند که GPT-4.5 در «مرزهای ممکن در یادگیری بدون نظارت» قرار دارد. این ادعا ممکن است درست باشد، اما محدودیتهای این مدل نیز به نظر میرسد گمانهزنیهای کارشناسان را تأیید میکند که «قوانین مقیاسپذیری» پیشآموزش دیگر به شکل گذشته پایدار نخواهند ماند.
ایلیا سوتسکور، همبنیانگذار OpenAI و دانشمند ارشد سابق این شرکت، در ماه دسامبر اظهار داشت که «ما به اوج دادهها رسیدهایم» و «پیشآموزش به شکلی که میشناسیم، بدون شک به پایان خواهد رسید.» این سخنان بازتابدهنده نگرانیهایی بود که سرمایهگذاران، بنیانگذاران و پژوهشگران حوزه هوش مصنوعی در گفتوگو با تِککرانچ برای یک گزارش ویژه در ماه نوامبر مطرح کرده بودند.
در پاسخ به موانع پیشآموزش، صنعت هوش مصنوعی — از جمله OpenAI — به سمت مدلهای استدلالی روی آورده است. این مدلها در مقایسه با مدلهای بدون استدلال، برای انجام وظایف به زمان بیشتری نیاز دارند، اما عموماً از ثبات بیشتری برخوردارند. آزمایشگاههای هوش مصنوعی با افزایش زمان و قدرت محاسباتی که مدلهای استدلالی برای «فکر کردن» به مسائل اختصاص میدهند، اطمینان دارند که میتوانند قابلیتهای این مدلها را به طور قابلتوجهی بهبود بخشند.
OpenAI قصد دارد در نهایت سری مدلهای GPT خود را با سری استدلالی «o» ادغام کند و این فرآیند را با GPT-5 در اواخر سال جاری آغاز خواهد کرد. GPT-4.5 که گفته میشود آموزش آن هزینه هنگفتی داشته، چندین بار با تأخیر مواجه شده و نتوانسته انتظارات داخلی را برآورده کند، ممکن است به تنهایی تاج بنچمارکهای هوش مصنوعی را به دست نیاورد. اما OpenAI احتمالاً آن را به عنوان گامی به سوی چیزی بسیار قدرتمندتر در نظر میگیرد.









