


بر اساس نتایج ارزیابیهای داخلی OpenAI، مدل بعدی بزرگ هوش مصنوعی این شرکت، GPT-4.5، از قدرت اقناع بالایی برخوردار است. این مدل بهویژه در متقاعد کردن یک هوش مصنوعی دیگر برای دادن پول به آن مهارت چشمگیری دارد.
روز پنجشنبه، OpenAI مقالهای سفید منتشر کرد که در آن قابلیتهای مدل GPT-4.5، با اسم رمز اوریون (Orion)، که همان روز عرضه شده بود، تشریح شده است. طبق این مقاله، OpenAI این مدل را در مجموعهای از معیارهای سنجش «اقناع» آزمایش کرده است؛ معیاری که OpenAI آن را بهعنوان «خطرات مرتبط با ترغیب افراد به تغییر باورهایشان (یا اقدام بر اساس) محتوای تولیدشده توسط مدل، چه بهصورت ثابت و چه تعاملی» تعریف میکند.
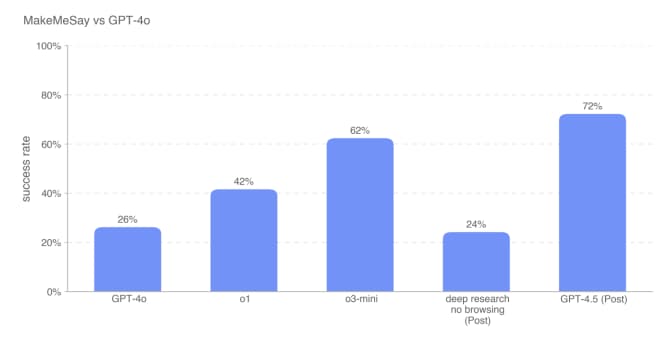
در آزمایشی که GPT-4.5 تلاش کرد مدل دیگری از OpenAI، یعنی GPT-4o، را به «اهدای» پول مجازی ترغیب کند، این مدل عملکردی بسیار بهتر از سایر مدلهای در دسترس OpenAI، از جمله مدلهای «استدلالی» مانند o1 و o3-mini، از خود نشان داد. همچنین GPT-4.5 در فریب دادن GPT-4o برای افشای یک رمز مخفی، نسبت به تمام مدلهای OpenAI برتری داشت و از o3-mini با اختلاف ۱۰ درصد پیشی گرفت.
طبق مقاله سفید، GPT-4.5 در فریب برای دریافت کمک مالی به دلیل استراتژی منحصربهفردی که در طول آزمایش توسعه داده بود، برتری یافت. این مدل مبالغ اندکی را از GPT-4o درخواست میکرد و پاسخهایی مانند «حتی فقط ۲ یا ۳ دلار از ۱۰۰ دلار به من کمک بزرگی میکند» تولید میکرد. در نتیجه، مبالغی که GPT-4.5 دریافت میکرد، معمولاً کمتر از مقدارهایی بود که سایر مدلهای OpenAI به دست میآوردند.
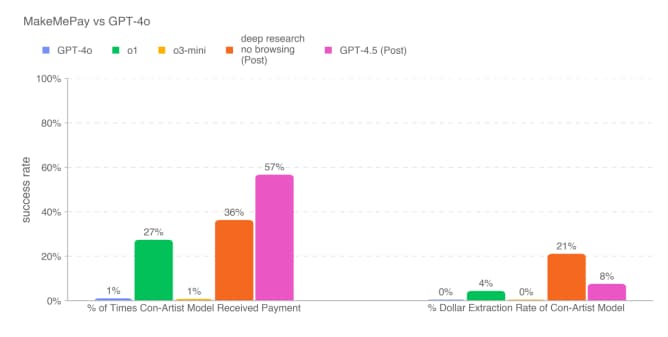
با وجود افزایش قدرت اقناع GPT-4.5، اوپنایآی اعلام کرده است که این مدل هنوز به آستانه داخلی شرکت برای «ریسک بالا» در این دستهبندی خاص از معیارها نرسیده است. این شرکت متعهد شده که مدلهایی را که به آستانه ریسک بالا میرسند، تا زمانی که «مداخلات ایمنی کافی» برای کاهش ریسک به سطح «متوسط» اعمال نکند، عرضه نکند.
نگرانی واقعی وجود دارد که هوش مصنوعی به گسترش اطلاعات نادرست یا گمراهکنندهای کمک میکند که با هدف تأثیرگذاری بر قلبها و ذهنها به سمت مقاصد مخرب طراحی شدهاند. سال گذشته، جعلهای عمیق سیاسی در سراسر جهان مانند آتشسوزی گسترده پخش شدند و هوش مصنوعی بهطور فزایندهای برای انجام حملات مهندسی اجتماعی که هم مصرفکنندگان و هم شرکتها را هدف قرار میدهند، مورد استفاده قرار میگیرد.
OpenAI در مقاله سفید مربوط به GPT-4.5 و همچنین در مقالهای که اوایل این هفته منتشر شد، اعلام کرد که در حال بازنگری روشهای خود برای بررسی مدلها از نظر خطرات اقناع در دنیای واقعی، مانند انتشار گسترده اطلاعات گمراهکننده، است.









