


مطالعه مایکروسافت نشان میدهد که مدلهای هوش مصنوعی هنوز در رفع اشکالات نرمافزاری با مشکل مواجه هستند.
مدلهای هوش مصنوعی از OpenAI، Anthropic و دیگر آزمایشگاههای برتر هوش مصنوعی به طور فزایندهای برای کمک به وظایف برنامهنویسی مورد استفاده قرار میگیرند. ساندار پیچای، مدیرعامل گوگل، در ماه اکتبر گفت که ۲۵ درصد از کد جدید در این شرکت توسط هوش مصنوعی تولید میشود، و مارک زاکربرگ، مدیرعامل متا، نیز تمایلات خود را برای استقرار گسترده مدلهای کدنویسی هوش مصنوعی در این غول رسانههای اجتماعی ابراز کرده است.
با این حال، حتی برخی از بهترین مدلهای امروزی نیز برای رفع اشکالات نرمافزاری که برای توسعهدهندگان باتجربه مشکلی ایجاد نمیکند، با مشکل مواجه هستند.
یک مطالعه جدید از Microsoft Research، بخش تحقیق و توسعه مایکروسافت، نشان میدهد که مدلها، از جمله Claude 3.7 Sonnet از Anthropic و o3-mini از OpenAI، در رفع بسیاری از مشکلات در یک معیار ارزیابی توسعه نرمافزار به نام SWE-bench Lite با شکست مواجه میشوند. این نتایج یادآوری هشیارانهای است که علیرغم اظهارات جسورانه شرکتهایی مانند OpenAI، هوش مصنوعی هنوز در زمینههایی مانند کدنویسی حریف متخصصان انسانی نیست.
نویسندگان مشترک این مطالعه نه مدل مختلف را به عنوان ستون فقرات یک “عامل مبتنی بر یک دستور” آزمایش کردند که به تعدادی از ابزارهای اشکالزدایی، از جمله یک اشکالزدای پایتون، دسترسی داشت. آنها این عامل را موظف به حل یک مجموعه انتخاب شده از ۳۰۰ وظیفه اشکالزدایی نرمافزار از SWE-bench Lite کردند.
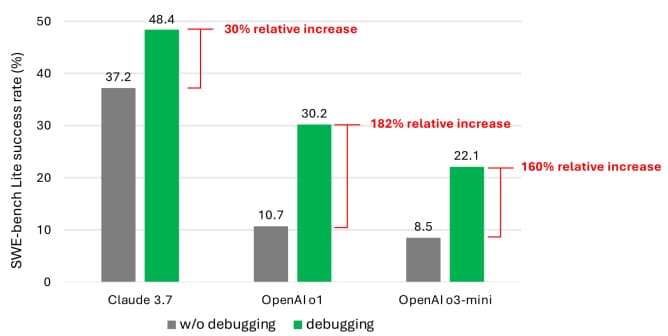
به گفته نویسندگان مشترک، حتی زمانی که عامل آنها به مدلهای قویتر و جدیدتر مجهز بود، به ندرت بیش از نیمی از وظایف اشکالزدایی را با موفقیت به پایان رساند. Claude 3.7 Sonnet بالاترین نرخ موفقیت متوسط (۴۸.۴%) را داشت، و پس از آن o1 OpenAI (30.2%) و o3-mini (22.1%) قرار داشتند.
چرا عملکرد ناامیدکننده بود؟ برخی از مدلها در استفاده از ابزارهای اشکالزدایی موجود و درک اینکه چگونه ابزارهای مختلف ممکن است در حل مشکلات مختلف کمک کنند، مشکل داشتند. با این حال، مشکل بزرگتر، به گفته نویسندگان مشترک، کمبود داده بود. آنها حدس میزنند که داده کافی که نشاندهنده “فرآیندهای تصمیمگیری متوالی” – یعنی ردیابیهای اشکالزدایی انسانی – باشد، در دادههای آموزشی مدلهای فعلی وجود ندارد.
نویسندگان مشترک در مطالعه خود نوشتند: “ما قویاً معتقدیم که آموزش یا تنظیم دقیق [مدلها] میتواند آنها را به اشکالزداهای تعاملی بهتری تبدیل کند. با این حال، این امر مستلزم دادههای تخصصی برای انجام چنین آموزش مدلی است، به عنوان مثال، دادههای مسیر که تعامل عوامل با یک اشکالزدا را برای جمعآوری اطلاعات لازم قبل از پیشنهاد رفع اشکال ثبت میکند.”
این یافتهها دقیقاً تکاندهنده نیستند. بسیاری از مطالعات نشان دادهاند که هوش مصنوعی تولید کننده کد تمایل به معرفی آسیبپذیریهای امنیتی و خطاها دارد، که ناشی از ضعف در زمینههایی مانند توانایی درک منطق برنامهنویسی است. یک ارزیابی اخیر از Devin، یک ابزار محبوب کدنویسی هوش مصنوعی، نشان داد که این ابزار تنها میتواند سه مورد از ۲۰ تست برنامهنویسی را تکمیل کند.
اما کار مایکروسافت یکی از دقیقترین بررسیها در مورد یک حوزه مشکلساز پایدار برای مدلها است. احتمالاً اشتیاق سرمایهگذاران به ابزارهای کمکی کدنویسی مبتنی بر هوش مصنوعی را کاهش نخواهد داد، اما امیدواریم که توسعهدهندگان – و مافوقهای آنها – را به فکر فرو ببرد که آیا اجازه دهند هوش مصنوعی به تنهایی مسئولیت کدنویسی را بر عهده بگیرد یا خیر.
گفتنی است، تعداد فزایندهای از رهبران فناوری با این تصور که هوش مصنوعی مشاغل کدنویسی را خودکار خواهد کرد، مخالفت کردهاند. بیل گیتس، بنیانگذار مایکروسافت، گفته است که معتقد است برنامهنویسی به عنوان یک حرفه ماندگار است. مدیرعامل Replit، امجد مساد، مدیرعامل Okta، تاد مککینون، و مدیرعامل IBM، آرویند کریشنا نیز همین نظر را دارند.
منبع: تککرانچ









