


حتی پوکمون هم از جنجالهای محکزنی هوش مصنوعی در امان نیست.
هفته گذشته، یک پست در X وایرال شد و ادعا کرد که جدیدترین مدل Gemini گوگل از مدل پرچمدار Claude آنتروپیک در سهگانه بازی ویدیویی اصلی پوکمون پیشی گرفته است. طبق گزارشها، Gemini در یک استریم Twitch یک توسعهدهنده به Lavender Town رسیده بود؛ Claude تا اواخر فوریه در Mount Moon گیر کرده بود.
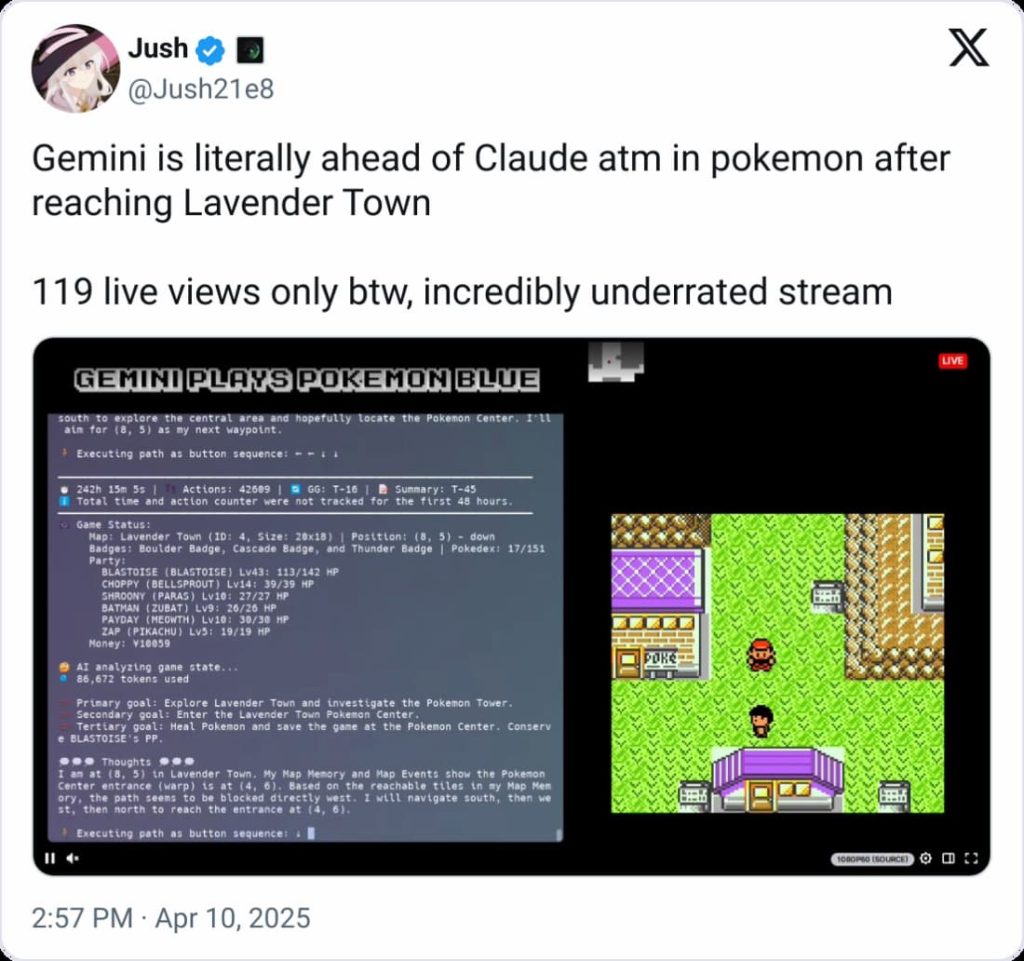
اما آنچه این پست به آن اشاره نکرد این بود که Gemini یک مزیت داشت.
همانطور که کاربران در Reddit اشاره کردند، توسعهدهندهای که استریم Gemini را نگهداری میکند، یک minimap سفارشی ساخته بود که به مدل کمک میکند “تایلها” را در بازی مانند درختان قابل برش شناسایی کند. این امر نیاز Gemini به تجزیه و تحلیل اسکرینشاتها قبل از تصمیمگیری در مورد گیمپلی را کاهش میدهد.
اکنون، پوکمون در بهترین حالت یک محکزنی نیمهجدی هوش مصنوعی است – تعداد کمی استدلال میکنند که این یک آزمایش بسیار آموزنده از قابلیتهای یک مدل است. اما این یک مثال آموزنده از چگونگی تأثیرگذاری پیادهسازیهای مختلف یک محکزنی بر نتایج است.
برای مثال، آنتروپیک دو امتیاز برای مدل اخیر Anthropic 3.7 Sonnet خود در محکزنی SWE-bench Verified، که برای ارزیابی تواناییهای کدنویسی یک مدل طراحی شده است، گزارش کرد. Claude 3.7 Sonnet در SWE-bench Verified دقت ۶۲.۳% و با یک “داربست سفارشی” که آنتروپیک توسعه داده بود، دقت ۷۰.۳% را به دست آورد.
اخیراً، متا نسخهای از یکی از مدلهای جدیدتر خود، Llama 4 Maverick، را برای عملکرد خوب در یک محکزنی خاص، LM Arena، تنظیم دقیق کرد. نسخه اصلی این مدل در همان ارزیابی به طور قابل توجهی بدتر عمل میکند.
با توجه به اینکه محکزنیهای هوش مصنوعی – از جمله پوکمون – از ابتدا معیارهای ناقصی هستند، پیادهسازیهای سفارشی و غیراستاندارد تهدید میکنند که اوضاع را حتی بیشتر مبهم کنند. به عبارت دیگر، به نظر نمیرسد که مقایسه مدلها با عرضه آنها آسانتر شود.
منبع: تککرانچ









