


بحثها درباره بنچمارکهای هوش مصنوعی و نحوه گزارشدهی آنها توسط آزمایشگاههای هوش مصنوعی، به تدریج به عرصه عمومی کشیده شده است.
این هفته، یکی از کارکنان OpenAI، شرکت هوش مصنوعی ایلان ماسک، xAI، را به انتشار نتایج گمراهکننده بنچمارک برای مدل هوش مصنوعی جدید خود، Grok 3، متهم کرد. ایگور بابوشکین، یکی از بنیانگذاران xAI، اصرار داشت که شرکت در این مورد حق دارد.
حقیقت در جایی میان این دو طرف است.
در یک پست در وبلاگ xAI، این شرکت نموداری منتشر کرد که عملکرد Grok 3 را در آزمون AIME 2025 نشان میداد. AIME مجموعهای از سوالات ریاضی چالشبرانگیز از یک آزمون ریاضی دعوتی اخیر است. برخی از کارشناسان اعتبار AIME را به عنوان یک بنچمارک برای هوش مصنوعی زیر سوال بردهاند، با این حال، نسخههای مختلف AIME، از جمله AIME 2025، به طور معمول برای بررسی تواناییهای ریاضی مدلها استفاده میشوند.
نمودار xAI نشان داد که دو نسخه از Grok 3، یعنی Grok 3 Reasoning Beta و Grok 3 mini Reasoning، در آزمون AIME 2025 از بهترین مدل موجود OpenAI، یعنی o3-mini-high، پیشی گرفتهاند. اما کارکنان OpenAI در X به سرعت اشاره کردند که نمودار xAI امتیاز AIME 2025 مدل o3-mini-high را در حالت “cons@64” شامل نکرده است.
شاید از خود بپرسید “cons@64” چیست؟ این اصطلاح مخفف “consensus@64” است و به این معنی است که مدل ۶۴ بار تلاش میکند تا به هر سوال در یک بنچمارک پاسخ دهد و پاسخهایی که بیشتر تکرار میشوند به عنوان پاسخ نهایی در نظر گرفته میشود. همانطور که تصور میکنید، cons@64 معمولاً باعث میشود که امتیاز بنچمارک مدلها به طور قابل توجهی افزایش یابد، و حذف آن از نمودار میتواند باعث شود که به نظر برسد یک مدل از مدل دیگری پیشی گرفته است، در حالی که در واقع چنین نیست.
امتیازهای Grok 3 Reasoning Beta و Grok 3 mini Reasoning برای AIME 2025 در حالت “@۱” (یعنی اولین امتیازی که مدلها در بنچمارک به دست آوردهاند) پایینتر از امتیاز o3-mini-high است. همچنین Grok 3 Reasoning Beta کمی از مدل o1 OpenAI در حالت “medium” محاسباتی عقبتر است. با این حال، xAI همچنان Grok 3 را به عنوان “هوشمندترین هوش مصنوعی جهان” تبلیغ میکند.
بابوشکین در X ادعا کرد که OpenAI در گذشته نمودارهای بنچمارک مشابهی منتشر کرده که گمراهکننده بودهاند، هرچند این نمودارها عملکرد مدلهای خود OpenAI را مقایسه میکردند. یک طرف بیطرف در این مناظره نموداری “دقیقتر” آماده کرد که عملکرد تقریبا تمام مدلها را در حالت cons@64 نشان میدهد.
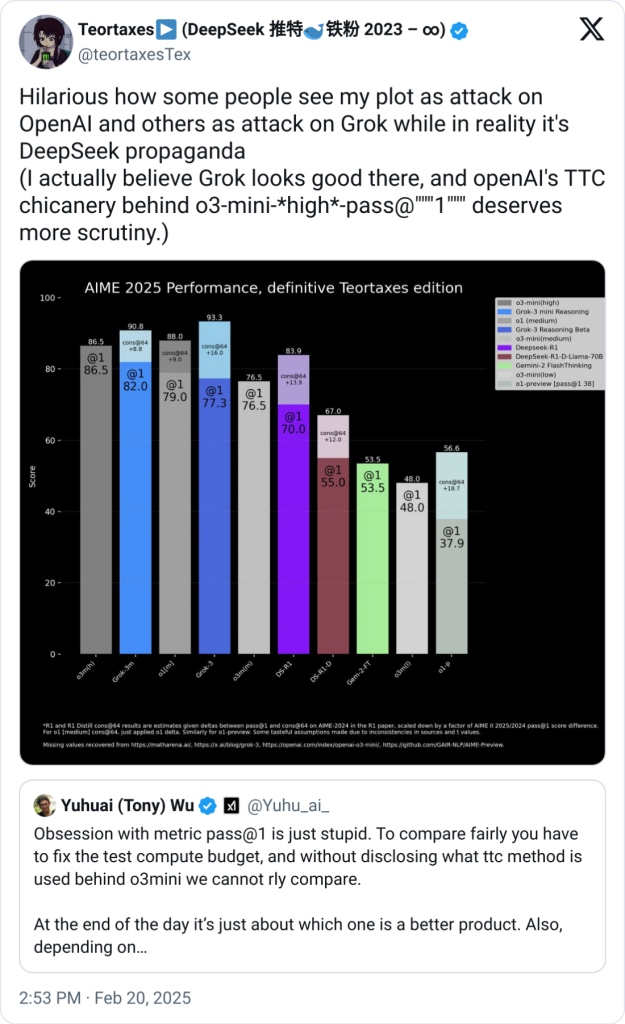
اما همانطور که محقق هوش مصنوعی، ناتان لمبرت، در یک پست اشاره کرد، شاید مهمترین معیار همچنان یک معما باشد: هزینه محاسباتی (و مالی) که هر مدل برای دستیابی به بهترین امتیاز خود متحمل شده است. این موضوع نشان میدهد که بیشتر بنچمارکهای هوش مصنوعی چه مقدار اطلاعات کمی درباره محدودیتها و نقاط قوت مدلها ارائه میدهند.
منبع: تککرانچ









