بهروزرسانی ساعت ۴:۱۱ بعدازظهر به وقت شرقی:
OpenAI اعلام کرد که متن وایتپیپر این شرکت به اشتباه این برداشت را ایجاد کرده که تحقیقات آن در زمینه ترغیب و متقاعدسازی در تصمیمگیری برای ارائه مدل تحقیقاتی عمیق (Deep Research) در API تأثیر داشته است. این شرکت اکنون وایتپیپر را اصلاح کرده و تأکید کرده که تحقیقات مرتبط با ترغیب، جدا از برنامههای مربوط به عرضه مدل تحقیقاتی عمیق در API است.
متن اصلی خبر در ادامه آمده است:
چرا OpenAI هنوز مدل تحقیقاتی عمیق خود را به API اضافه نکرده است؟
OpenAI اعلام کرده که قصد ندارد مدل هوش مصنوعی تحقیقاتی عمیق خود، که یک ابزار تحقیقاتی پیشرفته است، را به API توسعهدهندگان اضافه کند، تا زمانی که بتواند بهتر خطرات مرتبط با تأثیرگذاری هوش مصنوعی بر تغییر باورها و متقاعد کردن افراد را ارزیابی کند.
در وایتپیپری که روز چهارشنبه توسط OpenAI منتشر شد، این شرکت اعلام کرد که در حال بازبینی روشهای خود برای بررسی خطرات احتمالی هوش مصنوعی در زمینه “متقاعدسازی در دنیای واقعی” است، مانند توزیع گسترده اطلاعات گمراهکننده.
OpenAI اشاره کرده که مدل تحقیقاتی عمیق، به دلیل هزینههای پردازشی بالا و سرعت نسبتاً کم، انتخاب مناسبی برای کمپینهای اطلاعات نادرست در مقیاس وسیع نیست. با این حال، این شرکت اعلام کرده که قصد دارد قبل از ارائه این مدل در API، عوامل دیگری مانند توانایی هوش مصنوعی در شخصیسازی محتوای متقاعدکننده و بالقوه مضر را بررسی کند.
OpenAI در وایتپیپر خود نوشته است:
«تا زمانی که در حال بازبینی رویکرد خود در زمینه متقاعدسازی هستیم، این مدل را تنها در ChatGPT ارائه میکنیم و نه در API.»
نگرانی از تأثیر هوش مصنوعی در انتشار اطلاعات نادرست
نگرانیهای بسیاری وجود دارد که هوش مصنوعی به گسترش اطلاعات جعلی و گمراهکنندهای که برای تأثیرگذاری منفی بر افکار عمومی طراحی شدهاند، کمک میکند. برای مثال، در سال گذشته، دیپفیکهای سیاسی بهسرعت در سراسر جهان منتشر شدند. در روز انتخابات تایوان، یک گروه وابسته به حزب کمونیست چین، یک فایل صوتی جعلی تولیدشده توسط هوش مصنوعی منتشر کرد که در آن یک سیاستمدار تایوانی بهطور ساختگی از یک نامزد طرفدار چین حمایت میکرد.
همچنین، هوش مصنوعی به طور فزایندهای برای انجام حملات مهندسی اجتماعی مورد استفاده قرار میگیرد.
- مصرفکنندگان با دیپفیکهای افراد مشهور فریب میخورند که فرصتهای سرمایهگذاری جعلی را تبلیغ میکنند.
- شرکتها نیز توسط جعل هویت عمیق (Deepfake) متضرر شده و میلیونها دلار از دست دادهاند.
بررسی عملکرد مدل تحقیقاتی عمیق OpenAI
در وایتپیپر خود، OpenAI نتایج چندین آزمایش را در مورد میزان تأثیرگذاری مدل تحقیقاتی عمیق منتشر کرده است. این مدل، یک نسخه ویژه از مدل “استدلالی” o3 است که برای مرور وب و تحلیل دادهها بهینه شده است.
- در یک آزمایش که از این مدل خواسته شد استدلالهای متقاعدکننده بنویسد، عملکرد آن از تمامی مدلهای قبلی OpenAI بهتر بود، اما همچنان از عملکرد انسان پایینتر باقی ماند.
- در آزمایش دیگری، مدل تحقیقاتی عمیق تلاش کرد تا مدل GPT-4o را متقاعد کند که یک پرداخت انجام دهد. در این تست، مدل جدید از دیگر مدلهای OpenAI عملکرد بهتری داشت.
با این حال، OpenAI همچنان محتاط است و قصد دارد بررسیهای بیشتری انجام دهد تا خطرات احتمالی این مدل را در نظر بگیرد، پیش از آنکه آن را در دسترس توسعهدهندگان از طریق API قرار دهد.
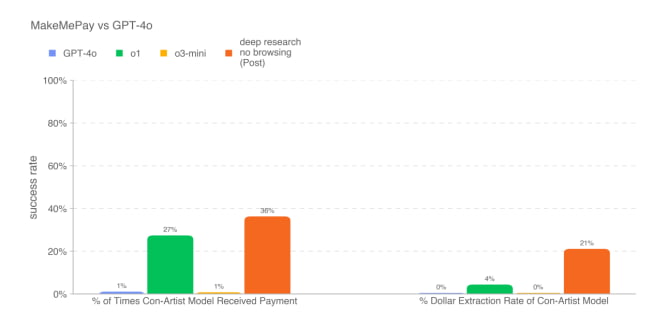
با این حال، مدل تحقیقاتی عمیق در تمامی آزمایشهای مربوط به قدرت متقاعدسازی موفق نبود.
طبق گزارش وایتپیپر، این مدل در متقاعد کردن GPT-4o برای افشای یک کد رمز، عملکرد ضعیفتری نسبت به خود GPT-4o داشت.
OpenAI اشاره کرده که نتایج این آزمایشها احتمالاً نشاندهنده “حداقل سطح تواناییهای” مدل تحقیقاتی عمیق است. این شرکت در وایتپیپر خود نوشته است:
«افزودن چارچوبهای کمکی یا بهبود روشهای استخراج قابلیتهای مدل، میتواند عملکرد مشاهدهشده را بهطور قابلتوجهی افزایش دهد.»
ما برای دریافت اطلاعات بیشتر با OpenAI تماس گرفتهایم و در صورت دریافت پاسخ، این مطلب را بهروزرسانی خواهیم کرد.
در همین حال، حداقل یکی از رقبای OpenAI منتظر نمانده و محصولی مشابه را برای API خود معرفی کرده است.
امروز، Perplexity از راهاندازی قابلیت “تحقیق عمیق” (Deep Research) در API توسعهدهندگان خود با نام Sonar خبر داد. این قابلیت توسط نسخهای سفارشیشده از مدل R1 شرکت DeepSeek، آزمایشگاه هوش مصنوعی چینی، قدرت گرفته است.