

مقدمه
در دنیای پرشتاب امروز، دادهها به عنوان یکی از ارزشمندترین داراییهای بشر شناخته میشوند. با رشد نمایی حجم دادههای تولیدشده، اهمیت استفاده از این دادهها در تحلیلها، پیشبینیها و تصمیمگیریها بهطور چشمگیری افزایش یافته است. با این حال، دادهها بهندرت در قالبی ایدهآل برای استفاده در مدلهای یادگیری ماشین و تحلیلهای آماری در دسترس هستند. این امر، نیاز به پیشپردازش دادهها را برجستهتر میکند.
نرمالسازی (Normalization) و استانداردسازی (Standardization) دو تکنیک کلیدی در پیشپردازش دادهها هستند که نقش مهمی در بهبود عملکرد مدلهای یادگیری ماشین ایفا میکنند. این روشها با هدف مقیاسگذاری دادهها به گونهای که متغیرها در یک محدوده معین یا توزیع معین قرار گیرند، طراحی شدهاند. عدم استفاده از این تکنیکها میتواند منجر به ناپایداری مدلها، کاهش دقت پیشبینیها و حتی شکست در فرآیند یادگیری شود.
در حالی که نرمالسازی و استانداردسازی در بسیاری از پروژههای علمی و عملی بهطور گسترده مورد استفاده قرار میگیرند، هنوز پرسشهای تحقیقاتی بسیاری در این حوزه باقی است. پژوهشهای اخیر نشان دادهاند که انتخاب تکنیک مناسب برای مقیاسگذاری میتواند تأثیر بسزایی در عملکرد مدلها داشته باشد. علاوه بر این، چالشهای مربوط به دادههای حجیم، مقادیر پرت، و دادههای غیرایستا، نیازمند روشهای پیشرفتهتر و تطبیقی در این زمینه هستند.
این مقاله با هدف بررسی دقیق و جامع نرمالسازی و استانداردسازی، ضمن ارائه تعاریف و تفاوتهای این دو مفهوم، به مرور روشها و الگوریتمهای پیشرفته پرداخته و کاربردها، چالشها و روندهای آینده این حوزه را تحلیل میکند. امید است که این پژوهش بتواند بهعنوان منبعی ارزشمند برای دانشجویان و علاقهمندان به یادگیری ماشین و تحلیل دادهها مورد استفاده قرار گیرد.
تفاوت نرمالسازی و استانداردسازی
پیشپردازش دادهها بهعنوان یکی از مراحل حیاتی در فرآیند یادگیری ماشین، نقش مهمی در آمادهسازی دادهها برای مدلسازی ایفا میکند. دو تکنیک رایج در این مرحله، نرمالسازی و استانداردسازی هستند که هرچند اهداف مشابهی را دنبال میکنند، اما در اصول و کاربردها تفاوتهای بنیادینی دارند.
تعریف نرمالسازی (Normalization)
نرمالسازی به فرآیندی اشاره دارد که در آن مقادیر دادهها به یک محدوده مشخص، معمولاً [۰,۱] یا [−۱,۱]، مقیاسبندی میشوند. هدف از این کار، جلوگیری از تأثیرگذاری مقادیر بزرگتر بر نتایج مدلهای یادگیری است. نرمالسازی بهویژه در مواردی که الگوریتمهای مبتنی بر فاصله (مانند K-Nearest Neighbors یا K-Means) استفاده میشوند، اهمیت دارد، زیرا این الگوریتمها به بزرگی مقیاس دادهها حساس هستند.
رایجترین فرمول نرمالسازی Min-Max Scaling است که به صورت زیر تعریف میشود:
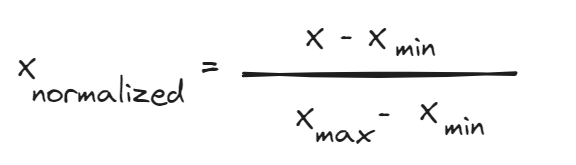
در این فرمول، Xmin و Xmax به ترتیب کوچکترین و بزرگترین مقدار متغیر X هستند.
تعریف استانداردسازی (Standardization)
استانداردسازی فرآیندی است که طی آن دادهها به یک توزیع با میانگین صفر و انحراف معیار یک تبدیل میشوند. این تکنیک بیشتر در الگوریتمهایی که بر پایه توزیع آماری عمل میکنند (مانند رگرسیون خطی یا الگوریتمهای مبتنی بر شبکههای عصبی) مؤثر است. استانداردسازی همچنین برای دادههایی که در مقیاسهای مختلف اندازهگیری شدهاند، بسیار مناسب است.
فرمول استانداردسازی به شکل زیر است:
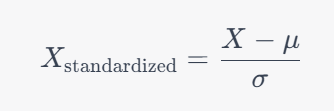
در این فرمول، μ میانگین و σ انحراف معیار متغیر X هستند. این تبدیل تضمین میکند که دادهها دارای یک توزیع نرمال استاندارد (Standard Normal Distribution) باشند.
مقایسه نرمالسازی و استانداردسازی
| ویژگی | نرمالسازی | استانداردسازی |
| هدف | مقیاسبندی دادهها به یک محدوده ثابت | تبدیل دادهها به توزیع با میانگین صفر و انحراف معیار یک |
| فرمول رایج | Min-Max Scaling | Z-Score Normalization |
| موارد کاربرد | الگوریتمهای مبتنی بر فاصله | الگوریتمهای مبتنی بر توزیع آماری |
| حساسیت به دادههای پرت | بالا (دادههای پرت میتوانند تأثیرگذار باشند) | کم (نسبت به دادههای پرت مقاومتر است) |
| محدوده مقادیر | معمولاً [۰, ۱] | نامحدود |
کاربردهای متفاوت در مدلهای یادگیری ماشین
- نرمالسازی:
- الگوریتمهایی مانند KNN و K-Means که به فاصلهها متکی هستند، به نرمالسازی نیاز دارند، زیرا مقادیر بزرگتر میتوانند بر فاصلهها غالب شوند.
- استانداردسازی:
- الگوریتمهایی مانند رگرسیون خطی، رگرسیون لجستیک، و شبکههای عصبی که بر توزیع دادهها متکی هستند، با دادههای استانداردسازیشده عملکرد بهتری دارند.
در حالی که نرمالسازی و استانداردسازی هر دو به بهبود کیفیت دادهها برای مدلسازی کمک میکنند، انتخاب مناسبترین تکنیک به نوع دادهها و الگوریتم مورد استفاده بستگی دارد. درک دقیق تفاوتها و موارد کاربرد این دو روش، گامی کلیدی در بهبود عملکرد مدلهای یادگیری ماشین محسوب میشود.
روشها و الگوریتمهای پیشرفته نرمالسازی و استانداردسازی
پیشپردازش دادهها از طریق نرمالسازی و استانداردسازی یکی از مراحل اساسی در یادگیری ماشین است. انتخاب روش مناسب و آشنایی با تکنیکهای پیشرفته میتواند تأثیر قابلتوجهی بر عملکرد مدلها داشته باشد. در این بخش، روشهای مختلف نرمالسازی و استانداردسازی، همراه با کاربردها و محدودیتهای آنها بررسی میشوند.

۱) روشهای نرمالسازی (Normalization Methods)
۱.۱) Min-Max Scaling
یکی از رایجترین روشهای نرمالسازی است که دادهها را به محدودهای ثابت (معمولاً [۰,۱]) مقیاس میکند. این روش بهویژه برای الگوریتمهای حساس به مقیاس، مانند KNN و K-Means، مناسب است.
فرمول:
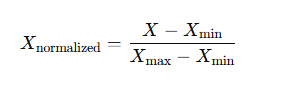
مزایا:
- ساده و سریع
- مناسب برای دادههای با محدوده مشخص
معایب:
- به دادههای پرت بسیار حساس است
- در صورت تغییر محدوده دادههای جدید، نیاز به محاسبه مجدد دارد
۲.۱) Scaling to Unit Norm
در این روش، مقادیر دادهها طوری تنظیم میشوند که بردار ویژگیها دارای طول واحد در فضای اقلیدسی باشد.
فرمول:
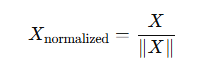
کاربردها:
الگوریتمهای مبتنی بر بردارهای ویژگی، مانند مدلهای یادگیری مبتنی بر متن (Text Embedding)
۳.۱) نرمالسازی غیرخطی (Non-linear Normalization)
این روشها از توابع غیرخطی، مانند لگاریتم یا ریشه دوم، برای نرمالسازی دادهها استفاده میکنند. این تکنیکها زمانی که توزیع دادهها به شدت نامتقارن است، کاربرد دارند.
فرمول نمونه:
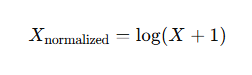
تکمیلی
روشهای نرمالسازی (Normalization) ابزارهای ساده و کارآمدی برای تغییر مقیاس دادهها به یک محدوده مشخص هستند. این تکنیکها معمولاً برای دادههایی استفاده میشوند که مقیاس آنها ممکن است بر عملکرد الگوریتم تأثیر بگذارد. الگوریتمهایی مانند KNN و K-Means به شدت به مقیاس دادهها وابستهاند و نرمالسازی میتواند با کاهش تأثیر مقادیر بزرگتر یا کوچکتر، نتایج مدل را بهبود بخشد. از مهمترین روشها در این حوزه، Min-Max Scaling است که دادهها را در محدوده [۰,۱] یا هر محدوده دلخواه دیگری تنظیم میکند. هرچند این روش بسیار ساده و سریع است، اما نسبت به دادههای پرت بسیار حساس میباشد. روش دیگری که به نام Scaling to Unit Norm شناخته میشود، برای مسائل مبتنی بر بردار ویژگیها کاربرد دارد و دادهها را به طول یک مقیاسبندی میکند. علاوه بر این، نرمالسازی غیرخطی (Non-linear Normalization) با استفاده از توابعی مانند لگاریتم، برای دادههایی که دارای توزیعهای نامتقارن هستند، بسیار مناسب است. انتخاب هر یک از این روشها باید با توجه به نوع دادهها، الگوریتم یادگیری و حساسیت مدل به مقیاس انجام شود. این تنوع در روشها امکان بهبود عملکرد مدلها در شرایط گوناگون را فراهم میکند.
۲) روشهای استانداردسازی (Standardization Methods)
۱.۲) Z-Score Normalization
این روش دادهها را بهگونهای مقیاسبندی میکند که میانگین دادهها صفر و انحراف معیار آن یک باشد.
فرمول:
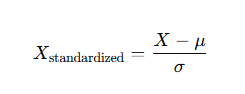
مزایا:
- مقاوم به تغییرات در محدوده دادهها
- مناسب برای دادههایی با توزیع تقریباً نرمال
معایب:
به فرض نرمال بودن دادهها وابسته است.
۲.۲) Robust Scaling
این روش، بهجای استفاده از میانگین و انحراف معیار، از مقادیر میانه و چارکها استفاده میکند.
فرمول:
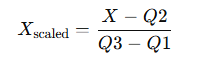
در این فرمول، Q2 میانه، و Q1 و Q3 به ترتیب چارک اول و سوم هستند.
مزایا:
- مقاوم به دادههای پرت
- مناسب برای دادههایی با توزیعهای غیرنرمال
۳.۲) استانداردسازی تطبیقی (Adaptive Scaling)
روشهای تطبیقی از الگوریتمهای یادگیری ماشین برای مقیاسبندی دادهها استفاده میکنند. این تکنیکها برای دادههای بزرگ و غیرایستا (Dynamic Data) طراحی شدهاند.
نمونهای از این روشها، استفاده از شبکههای عصبی خودرمزگذار (Autoencoder) برای یادگیری مقیاسبندی بهینه است.
تکمیلی
استانداردسازی (Standardization) یک فرآیند کلیدی در یادگیری ماشین است که دادهها را به گونهای تغییر میدهد که میانگین مقادیر صفر و انحراف معیار آنها برابر با یک باشد. این روش به طور خاص برای الگوریتمهایی که بر توزیع دادهها تکیه دارند، مانند رگرسیون خطی یا شبکههای عصبی، اهمیت دارد. استانداردسازی Z-Score یکی از رایجترین روشها در این زمینه است که دادهها را در مقیاسی با میانگین صفر و پراکندگی متعادل ارائه میکند. با این حال، این روش در مواردی که دادهها توزیع غیرنرمال دارند، بهینه عمل نمیکند. برای رفع این چالش، Robust Scaling معرفی شده است که از مقادیر میانه و چارکها استفاده میکند و به همین دلیل نسبت به دادههای پرت مقاوم است. همچنین، استانداردسازی تطبیقی (Adaptive Scaling) با استفاده از الگوریتمهای یادگیری، امکان مقیاسبندی بهینهتر را فراهم میآورد. این روشها بهویژه در دادههای بزرگ و پویا، مانند دادههای جریانی، کاربرد دارند. هرچند استانداردسازی نیازمند شناخت کافی از توزیع دادهها و ویژگیهای مجموعه داده است، اما بهعنوان یک ابزار بسیار کارآمد برای بهبود عملکرد مدلها شناخته میشود.
چالشها و مسائل مرتبط با نرمالسازی و استانداردسازی دادهها
با وجود اهمیت بالای نرمالسازی و استانداردسازی در پیشپردازش دادهها، این تکنیکها با چالشها و مسائل خاصی همراه هستند که میتوانند تاثیرات قابلتوجهی بر عملکرد مدلها بگذارند. در این بخش، به مهمترین مشکلات و چالشهای مربوط به این فرآیندها میپردازیم و روشهایی برای مواجهه با آنها پیشنهاد میدهیم.
۱) حساسیت به دادههای پرت (Outliers)
دادههای پرت (Outliers) دادههایی هستند که بهطور قابل توجهی با سایر نقاط داده متفاوت هستند. این دادهها میتوانند ناشی از خطاهای اندازهگیری، مشکلات ثبت دادهها، یا رفتارهای غیرمعمول در سیستم باشند. وجود دادههای پرت میتواند بهشدت بر روشهای نرمالسازی تأثیر بگذارد، بهویژه در تکنیکهایی مانند Min-Max Scaling که از مقادیر حداقل و حداکثر استفاده میکند.
به عنوان مثال، اگر دادهای با مقدار بسیار بالا یا بسیار پایین در مجموعه داده وجود داشته باشد، تمام دادههای دیگر به سمت مقادیر کوچکتر مقیاسبندی میشوند که میتواند باعث کاهش دقت مدل شود. راهکارهایی که برای مقابله با این مشکل پیشنهاد میشوند، عبارتند از:
- حذف دادههای پرت: در صورتی که دادههای پرت غیرمنطقی یا اشتباه باشند.
- استفاده از روشهای مقاوم مانند Robust Scaling که به جای میانگین و انحراف معیار، از میانه و چارکها برای مقیاسبندی استفاده میکند.
- شناسایی و اصلاح دادههای پرت با استفاده از الگوریتمهای تشخیص پرت (Outlier Detection)
این چالش بهویژه در پروژههایی با دادههای حساس، مانند پیشبینی بازارهای مالی یا تحلیل پزشکی، بسیار حیاتی است.
۲) انتخاب روش مناسب برای نوع دادهها
یکی از دشواریهای پیشپردازش دادهها، انتخاب روش نرمالسازی یا استانداردسازی مناسب برای نوع دادهها است. هر روش، با فرضیات و محدودیتهای خاص خود، برای شرایط مشخصی بهینه است. به عنوان مثال:
- Min-Max Scaling برای دادههایی که در بازه مشخصی قرار دارند و مقادیر پرت در آن کم است، ایدهآل است.
- Z-Score Standardization زمانی مناسب است که دادهها توزیعی نزدیک به نرمال داشته باشند.
- Non-linear Normalization برای دادههای با توزیع غیرخطی و بسیار نامتقارن مؤثر است.
یکی از مشکلات رایج، ترکیب دادههایی با ماهیتهای متفاوت است. برای مثال، دادههای عددی با دادههای برداری (مانند Embeddings) نیازمند روشهای متفاوتی هستند. تحقیقات نشان داده است که استفاده ترکیبی از چندین تکنیک مقیاسبندی میتواند در چنین مواردی مفید باشد. انتخاب روش مناسب نیازمند تحلیل دقیق ویژگیهای مجموعه داده و شناخت الگوریتمی است که قرار است استفاده شود.
۳) تغییرات در دادهها (Data Drift)
یکی از چالشهای مهم در یادگیری ماشین، تغییرات تدریجی یا ناگهانی در توزیع دادهها در طول زمان است که به آن Data Drift گفته میشود. این پدیده میتواند ناشی از عوامل مختلفی باشد، از جمله تغییرات در رفتار کاربران، شرایط محیطی، یا تغییرات سیستماتیک در فرآیند جمعآوری دادهها.
این تغییرات میتوانند بر مقیاس دادهها تأثیر بگذارند، بهویژه اگر مقیاسبندی بر اساس مقادیر قبلی (مانند میانگین یا انحراف معیار تاریخی) انجام شده باشد. به عنوان مثال، در یک سیستم پیشبینی فروش، تغییرات فصلی میتواند باعث تغییر توزیع دادهها شود و نرمالسازی قبلی دیگر مناسب نباشد.
راهحلهای پیشنهادی:
پایش مداوم تغییرات دادهها و اجرای مجدد فرآیند پیشپردازش در بازههای زمانی منظم
استفاده از روشهای Online Normalization که بهصورت بلادرنگ مقادیر میانگین و انحراف معیار را بهروزرسانی میکنند.
اعمال Adaptive Scaling برای تطبیق خودکار مدل با توزیع جدید دادهها
۴) پیچیدگیهای محاسباتی در دادههای بزرگ
حجم بالای دادهها در پروژههای یادگیری ماشین و دادهکاوی، فرآیند نرمالسازی و استانداردسازی را به یک چالش محاسباتی تبدیل کرده است. محاسبه میانگین، انحراف معیار، یا مقادیر حداقل و حداکثر در مجموعه دادههای بزرگ نیازمند زمان و منابع محاسباتی قابل توجهی است.
برای مثال، در پروژههایی که از دادههای جریانی (Streaming Data) استفاده میکنند، نیاز است که مقادیر نرمالسازی بهطور مداوم و بهروز شده در زمان واقعی محاسبه شوند. این امر نه تنها پیچیدگی الگوریتمی را افزایش میدهد، بلکه نیاز به طراحی معماریهای مقیاسپذیر نیز دارد.
راهکارها:
پردازش توزیعشده با استفاده از فناوریهایی مانند Hadoop و Spark
استفاده از تکنیکهای Batch Normalization، که دادهها را به صورت دستهای پردازش میکند و محاسبات را کارآمدتر میسازد.
بهرهگیری از توابع کاهشدهنده حافظه (Memory-efficient Reducers) برای محاسبات میانگین و انحراف معیار
۵) تأثیر بر مدلهای یادگیری عمیق
در مدلهای یادگیری عمیق، مقیاسبندی دادهها میتواند تأثیر مستقیم بر سرعت و دقت فرآیند آموزش داشته باشد. دادههایی که بهدرستی نرمالسازی یا استانداردسازی نشدهاند، ممکن است باعث ایجاد مقادیر بزرگ یا کوچک در ورودیها شوند که به نوبه خود باعث ناپایداری در وزنهای مدل میشود.
روشهای خاصی برای مقابله با این مشکل در یادگیری عمیق توسعه یافتهاند:
- Batch Normalization: به پایداری فرآیند یادگیری و افزایش سرعت همگرایی کمک میکند.
- Layer Normalization و Instance Normalization: برای تنظیم مقادیر فعالسازی در شبکههای بازگشتی و مدلهای پیچیده دیگر مناسب هستند.
هرچند این تکنیکها به بهبود عملکرد کمک میکنند، اما نیاز به تنظیمات دقیق دارند. برای مثال، مقدارهای بهینه برای پارامترهای نرمالسازی (مانند گاما و بتا در Batch Normalization) ممکن است بسته به نوع داده و معماری مدل متفاوت باشد.
نرمالسازی و استانداردسازی دادهها ابزارهای حیاتی در پیشپردازش دادهها هستند، اما همچنان با چالشهای مختلفی همراه هستند. حساسیت به دادههای پرت، انتخاب روش مناسب برای نوع دادهها، تغییرات در دادهها، پیچیدگیهای محاسباتی و تأثیرات بر مدلهای یادگیری عمیق از جمله چالشهایی هستند که میتوانند عملکرد این تکنیکها را تحت تأثیر قرار دهند. درک این مسائل و یافتن راهحلهای مناسب برای هر چالش، کلید موفقیت در استفاده بهینه از این تکنیکها در مدلهای یادگیری ماشین است.
تحقیقات پیشرفته و روندهای آینده در نرمالسازی و استانداردسازی
پیشرفتهای اخیر در یادگیری ماشین و دادهکاوی باعث توسعه روشهای جدید و بهینهتر برای نرمالسازی و استانداردسازی دادهها شده است. با رشد دادههای حجیم و پیچیده، نیاز به رویکردهای تطبیقی و پیشرفته در این حوزه بیشتر از گذشته احساس میشود. در این بخش به مهمترین پژوهشها و روندهای آینده در زمینه نرمالسازی و استانداردسازی میپردازیم.

۱) نرمالسازی و استانداردسازی تطبیقی (Adaptive Normalization and Standardization)
روشهای سنتی نرمالسازی و استانداردسازی از مقادیر ثابت مانند میانگین، انحراف معیار، یا حداقل و حداکثر دادهها استفاده میکنند. اما این رویکردها در دادههای پویا یا زمانی که توزیع دادهها تغییر میکند (پدیده Data Drift)، ممکن است ناکارآمد باشند. در روشهای تطبیقی، از الگوریتمهای یادگیری ماشین برای یادگیری مقیاس بهینه استفاده میشود.
به عنوان مثال، شبکههای عصبی خودرمزگذار (Autoencoders) میتوانند برای یادگیری ویژگیهای مهم دادهها بهکار گرفته شوند و سپس دادهها را بر اساس این ویژگیها مقیاسبندی کنند. این تکنیکها بهویژه برای دادههای غیرایستا، مانند دادههای جریانی یا سیستمهای توصیهگر که دادهها به مرور زمان تغییر میکنند، مفید هستند.
روشهای تطبیقی با استفاده از بهینهسازی دینامیک، امکان تنظیم مداوم مقیاس دادهها را فراهم میکنند، بهطوری که مدلها بتوانند خود را با شرایط جدید هماهنگ کنند. تحقیقات اخیر نشان دادهاند که این رویکردها میتوانند عملکرد مدلها را در مسائل حساس به تغییرات داده، مانند پیشبینی بازارهای مالی یا تحلیل دادههای حسگرها، به میزان قابل توجهی بهبود دهند.
۲) استفاده از نرمالسازی در یادگیری عمیق (Deep Learning)
در یادگیری عمیق، دادهها معمولاً از طریق لایههای متعدد پردازش میشوند که هر کدام دارای وزنها و مقیاسهای متفاوت هستند. این امر میتواند باعث شود که مقادیر فعالسازی در شبکه به شدت متغیر باشند، که در نتیجه فرآیند آموزش مدل ناپایدار شود یا نیاز به زمان بیشتری برای همگرایی داشته باشد.
برای مقابله با این مشکل، تکنیکهای نرمالسازی ویژهای در یادگیری عمیق توسعه یافتهاند:
- Batch Normalization: دادهها در هر لایه به صورت دستهای نرمالسازی میشوند. این روش پایداری آموزش و سرعت همگرایی را افزایش میدهد.
- Layer Normalization: این تکنیک مقادیر را در یک لایه کامل نرمالسازی میکند و برای مدلهای RNN (شبکههای عصبی بازگشتی) کاربرد بیشتری دارد.
- Instance Normalization: در مدلهایی مانند Style Transfer، برای نرمالسازی هر نمونه به صورت مستقل استفاده میشود.
پژوهشها نشان دادهاند که ترکیب این تکنیکها با دیگر روشهای بهینهسازی، مانند Dropout یا Weight Decay، میتواند به طور قابل توجهی عملکرد شبکههای عصبی عمیق را بهبود بخشد.
۳) ترکیب با الگوریتمهای خودکارسازی پیشپردازش (AutoML)
AutoML (یادگیری ماشین خودکار) به طور فزایندهای برای تسهیل و تسریع فرآیند مدلسازی مورد استفاده قرار میگیرد. یکی از اجزای کلیدی این رویکرد، خودکارسازی پیشپردازش دادهها، از جمله نرمالسازی و استانداردسازی، است.
در این فرآیند، سیستم AutoML میتواند با استفاده از الگوریتمهای یادگیری تقویتی یا بهینهسازی ترکیبی، بهترین تکنیک مقیاسبندی را برای مجموعه دادههای خاص انتخاب کند. به عنوان مثال، ابزارهایی مانند Google AutoML یا H2O.ai، به کاربران اجازه میدهند بدون نیاز به دانش عمیق در مورد نرمالسازی یا استانداردسازی، مدلهایی با عملکرد بالا ایجاد کنند.
این سیستمها معمولاً از دادههای تاریخی و دانش قبلی برای پیشبینی بهترین روش پیشپردازش استفاده میکنند و حتی میتوانند روشهای سفارشی برای مجموعه دادههای خاص ایجاد کنند. توسعه این فناوری میتواند به کاهش زمان و هزینههای پروژههای یادگیری ماشین کمک ک
۴) نرمالسازی برای دادههای چندبعدی و ناهمگن
دادههای چندبعدی و ناهمگن، شامل انواع مختلفی از دادهها، مانند دادههای عددی، متنی، تصویری، و صوتی هستند. هر یک از این انواع دادهها دارای ویژگیهای مقیاس و توزیع متفاوتی هستند که نرمالسازی آنها را پیچیده میکند.
برای مثال، دادههای تصویری معمولاً به مقیاس [۰,۲۵۵] محدود میشوند، در حالی که دادههای متنی میتوانند به صورت بردارهای پراکنده با دامنههای بسیار گسترده باشند. نرمالسازی این نوع دادهها نیازمند روشهایی است که بتوانند خصوصیات منحصر به فرد هر نوع داده را در نظر بگیرند.
تحقیقات جدید در این زمینه بر استفاده از تکنیکهای چندوجهی (Multi-modal Techniques) متمرکز شده است که دادهها را به صورت همزمان و متناسب نرمالسازی میکنند. برای مثال، ترکیب نرمالسازی بردارهای کلمه (Word Embeddings) با مقیاسبندی دادههای عددی در مسائل یادگیری ماشین ترکیبی (Hybrid Machine Learning) میتواند دقت و کارایی مدل را افزایش دهد.
۵) نرمالسازی در یادگیری فدرال (Federated Learning)
یادگیری فدرال یکی از زمینههای نوظهور در یادگیری ماشین است که در آن مدلها بدون نیاز به اشتراکگذاری دادههای خام بین دستگاهها یا سازمانها، آموزش داده میشوند. در این سیستم، دادهها توزیعشده و ناهمگن هستند، به این معنی که هر دستگاه میتواند مقادیر متفاوتی از دادهها با توزیعهای مختلف داشته باشد.
یکی از چالشهای اصلی در یادگیری فدرال، ایجاد روشهای نرمالسازی توزیعشده است که بدون نیاز به تبادل مقادیر واقعی دادهها، بتوانند ویژگیهای مقیاس دادهها را هماهنگ کنند. روشهای جدید در این حوزه از تکنیکهای رمزنگاری و یادگیری خصوصی (Privacy-preserving Techniques) استفاده میکنند تا دادهها را نرمالسازی کرده و در عین حال حریم خصوصی کاربران را حفظ کنند.
۶) استفاده از روشهای مبتنی بر هوش مصنوعی در پیشپردازش دادهها
یکی از موضوعات جالب و نوظهور، استفاده از هوش مصنوعی برای طراحی خودکار روشهای نرمالسازی و استانداردسازی است. شبکههای عصبی پیشرفته، مانند Transformers، میتوانند دادهها را تحلیل کرده و روشهای بهینه برای مقیاسبندی آنها را بیاموزند.
برای مثال، در دادههای پیچیده مانند دادههای ژنومی یا تصاویر پزشکی، این شبکهها قادرند روابط پیچیده بین ویژگیها را شناسایی کنند و مقیاسهای مناسب برای بهبود عملکرد مدل ارائه دهند. تحقیقات نشان میدهد که این تکنیکها، بهویژه در حوزههایی که دادهها دارای نویز یا مقادیر پرت هستند، عملکرد بسیار بهتری نسبت به روشهای سنتی دارند.
پیشرفتهای اخیر در زمینه نرمالسازی و استانداردسازی دادهها، تأکیدی بر اهمیت این تکنیکها در یادگیری ماشین و دادهکاوی دارند. رویکردهای تطبیقی، استفاده در یادگیری عمیق، و توسعه روشهای خاص برای دادههای توزیعشده یا چندبعدی، آینده این حوزه را شکل میدهند. این پیشرفتها نه تنها عملکرد مدلها را بهبود میبخشند، بلکه زمینهساز نوآوریهای بیشتری در حوزههای مختلف یادگیری ماشین خواهند شد.
نتیجهگیری
نرمالسازی و استانداردسازی دادهها به عنوان دو تکنیک اساسی در پیشپردازش دادهها، نقش بسیار مهمی در بهبود عملکرد مدلهای یادگیری ماشین و دادهکاوی دارند. این تکنیکها با هدف کاهش تأثیر تفاوتهای مقیاسی و ایجاد توزیعهای منظم در دادهها، به ایجاد مدلهایی پایدارتر و دقیقتر کمک میکنند.
در طول مقاله، به تفاوتها و کاربردهای این دو روش پرداخته شد. در حالی که نرمالسازی برای مقیاسبندی دادهها به محدودهای مشخص مفید است، استانداردسازی برای تنظیم توزیع دادهها به میانگین صفر و انحراف معیار یک مناسبتر میباشد. انتخاب صحیح این تکنیکها به نوع داده، الگوریتم مورد استفاده، و حساسیت به تغییرات در توزیع دادهها بستگی دارد.
همچنین، چالشهایی نظیر حساسیت به دادههای پرت، انتخاب روش مناسب، و مدیریت دادههای پویا به عنوان مسائل کلیدی شناسایی شدند. برای مواجهه با این چالشها، تحقیقات پیشرفتهای در زمینه روشهای تطبیقی، خودکارسازی پیشپردازش، و ترکیب با یادگیری عمیق صورت گرفته است. روندهای آینده نشان میدهند که استفاده از ابزارهای مبتنی بر هوش مصنوعی و روشهای پیشرفته مانند نرمالسازی توزیعشده، میتواند عملکرد مدلها را در حوزههای مختلف، از یادگیری عمیق گرفته تا یادگیری فدرال، بهبود دهد.
در نهایت، موفقیت در یادگیری ماشین به میزان زیادی به کیفیت دادهها و فرآیند پیشپردازش وابسته است. نرمالسازی و استانداردسازی، ابزاری ضروری در این مسیر هستند که دانشجویان، محققان، و متخصصان باید با تسلط بر آنها، پروژههای خود را به سطحی بالاتر ارتقا دهند.









