مدل دیپسیک-آروان آخرین ضربه در ضربآهنگ پیشرفت پیوسته هوشمصنوعی است. به دلایل زیر، این یک دستآورد بزرگ برای جامعه تحقیق و توسعه یادگیری ماشین محسوب میگردد:
یک مدل با وزنهای با دسترسی باز محسوب میشود، به همراه نسخههای کوچک شده و تقطیر دانش (distilled)
براساس به اشتراکگذاری و بازتاب از روش یادگیری، استدلال مدلی مانند OpenAI O1 را بازتولید میکند
در این مقاله بررسی خواهیم کرد که این مدل چگونه ساخته شده است. بخش زیادی از دانش پایهای برای درک چگونگی عملکرد چنین مدلی را میتوانید در کتاب Hands-On Large Language Models پیدا کنید.
یادآوری: چگونه مدلهای زبانی آموزش داده میشوند
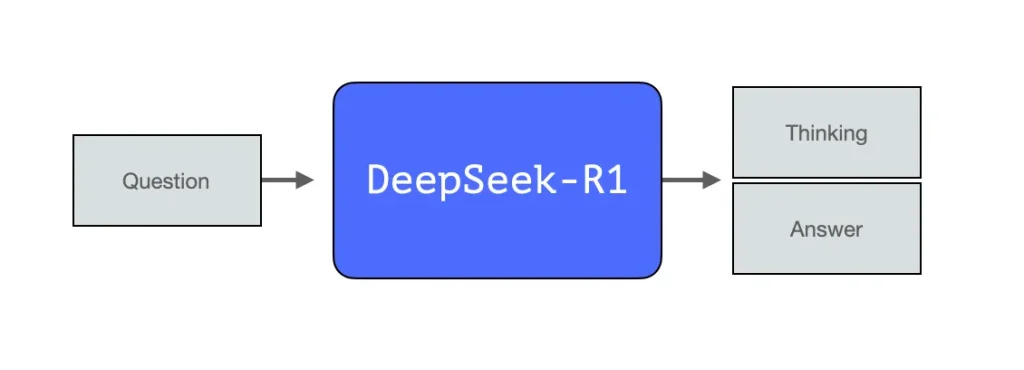
همانند سایر مدلهای زبانی بزرگ جالب، دیپسیک-آروان نیز در هر گام یک توکن را خلق میکند، به استثنای آن در حل مسائل ریاضی و استدلالی به دلیل صرف زمان پردازشی بیشتر برای یک مسئله از طریق فرایند خلق توکنهای (thinking tokens) که زنجیرهی تفکر آن را توضیح میدهند برتری مییابد.
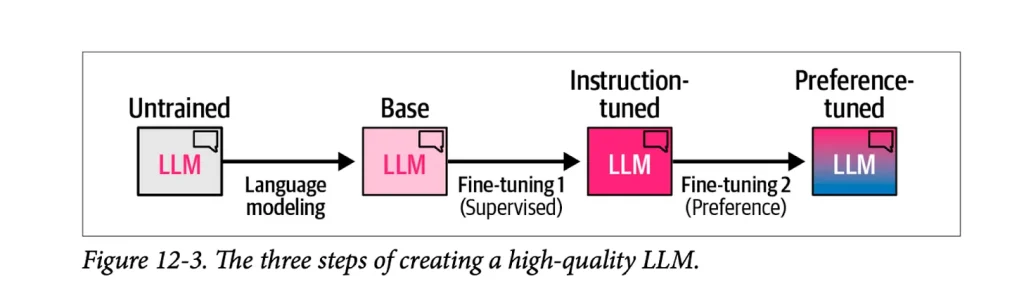
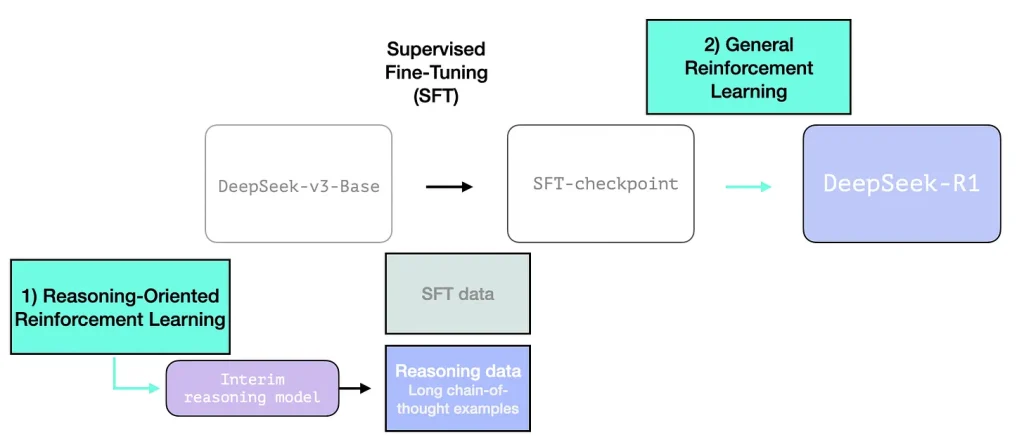
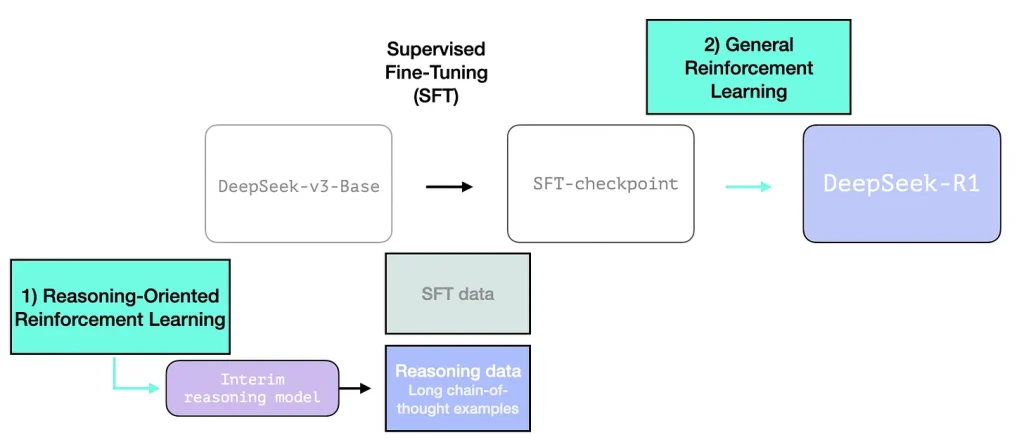
تصویری که در ادامه آورده شده است از فصل دوازدهم کتاب ما برداشته شده، و دستور عمومی ایجاد یک مدل زبانی بزرگ با کیفیت بالا را در سه گام نشان میدهد:
گام مدلسازی زبانی که در آن مدل برای پیشگویی واژه بعدی به کمک دادگان وب آموزش داده میشود. این مرحله یک مدل پایه را نتیجه میدهد.
گام تنطیم دقیق (fine-tuning) بانظارت که مفید بودن مدل در پرسشها و دستورالعملهای آتی را افزایش میدهد. این گام یک مدل دقیق شده (instruction tuned model) یا یک مدل بانظارت دقیقشده (supervised fine -tuning / SFT model) را نتیجه میدهد.
در انتها یک تنظیم دقیق رجحان (preference) اعمال میگردد که رفتار مدل را صیقل میدهد و با ترجیحات انسانی همتراز میگرداند، که مدل زبانی بزرگ نهایی که در اپها استفاده میشود را نتیجه میدهد.
دستور آموزش مدل دیپسیک-آروان
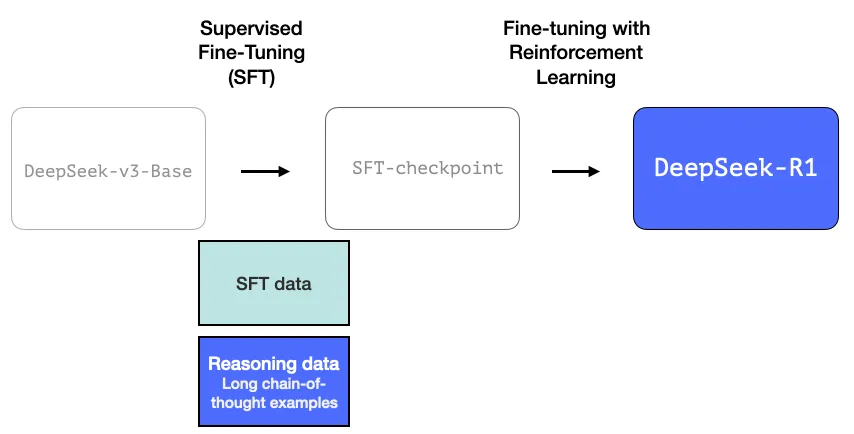
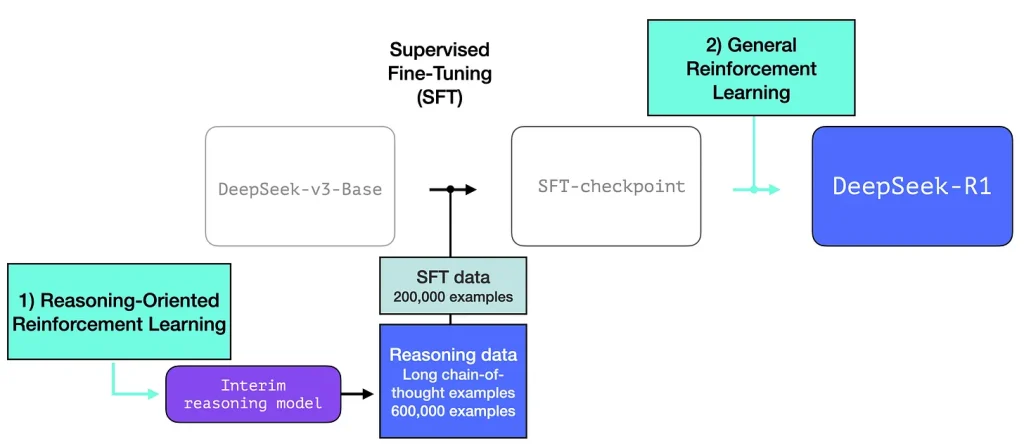
این مدل دستور عمومی که در ادامه میآید را رعایت میکند. جزییات مرحله اول در مقاله پیشین انتشار داده شده برای نسخه سوم مدل دیپسیک (DeepSeek-V3 model) آورده شده است. آروان از مدل پایه معرفی شده در این مقاله استفاده میکند (نه از مدل نهایی DeepSeek-V3 )، سپس وارد مرحله SFT و تنظیم دقیق رجحان میگردد، اما تفاوت اصلی آن در جزییات مشخص میشود.
سه مورد مهم در فرایند ایجاد آروان وجود دارد.
۱- زنجیره بلند دادگان SFT استدلال
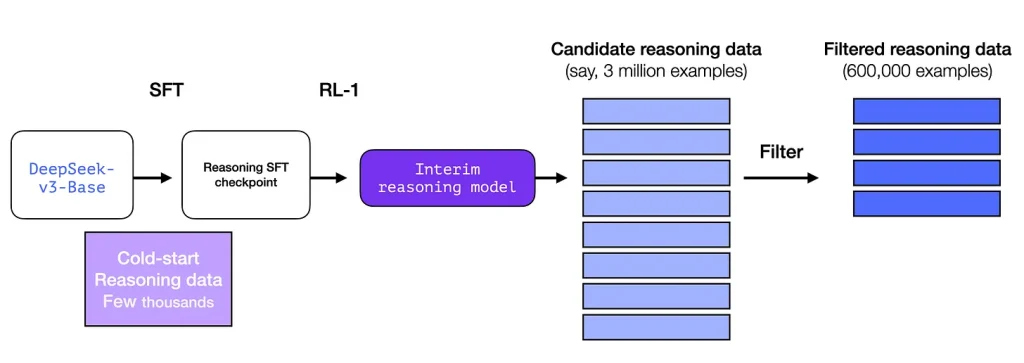
این فرایند از مجموعه زیادی از نمونههای استدلال زنجیره تفکر (chain-of-thought) بلند (۶۰۰.۰۰۰ عدد) تشکیل شده است. بهدست آوردن این نمونهها و برچسبگذاری انسانی آنها بسیار سخت و پرهزینه است. به همین علت فرایند ایجاد آنها دومین مورد بااهمیت این مدل است.
۲- یک مدل زبانی بزرگ باکیفیت موقت (با عملکرد ضعیف در تسکهای غیراستدلالی)
این دادگان به کمک پیشساز آوران ساخته شدهاند، که در استلال تخصص دارد اما برای آن نامی انتخاب نکردهاند. این مدل از یک مدل دیگر به نام آروان-زیرو (R1-Zero) الهام گرفته است که به صورت خلاصه آن را بررسی میکنیم. اهمیت این مدل به خاطر عالی بودن آن برای استفاده نیست، بلکه ایجاد آن به کمک مجموعه دادگان برچسبدار بسیار کمی در کنار یادگیری تقویتی در اِسْکِیل بزرگ، منجر به خلق مدلی شده که در مسائل مرتبط با استلال برتری یافته است.
خروجی این مدل بدون نام متخصص در زمینه استدلال، میتواند برای آموزش یک مدل عاممنظوره برای کارهای دیگر، نظیر تسکهای غیراستدلالی، که یک کاربر انتظار دارد مورد استفاده قرار گیرد.
۳- ایجاد مدلهای استدلالی به کمک یادگیری تقویتی در مقیاس بزرگ
این مسئله در دو گام اتفاق میافتد:
یادگیری تقویتی در جهت استدلال در مقیاس بزرگ
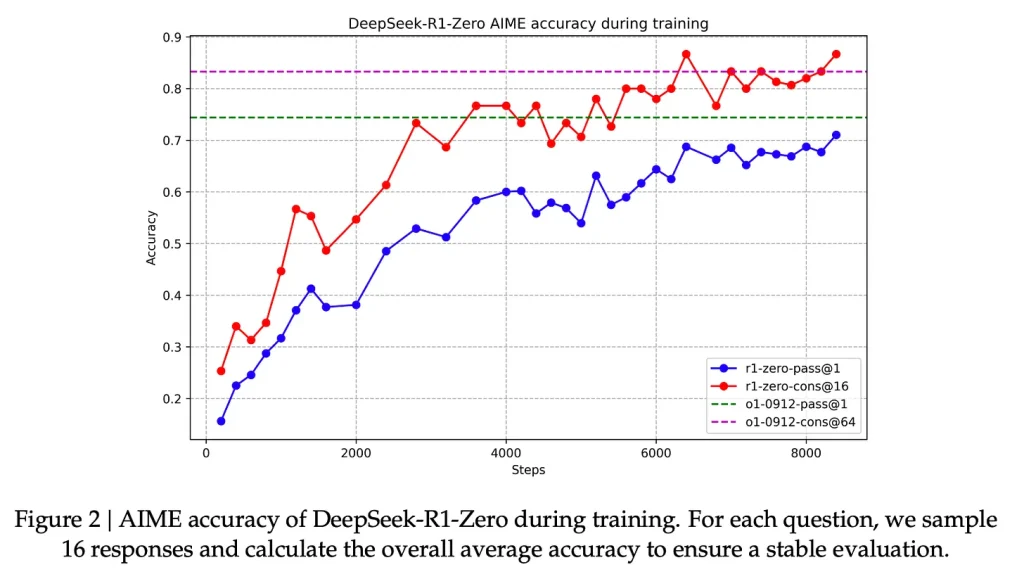
در این گام یادگیری تقویتی برای ایجاد مدل استدلالی وقت استفاده میشود. این مدل برای خلق نمونههای استدلالی SFT استفاده میگردد. چیزی که ایجاد این مدل را امکانپذیر میکند، آزمایشی اولیه است که منجر به حلق مدل دیپسیک-آروان-زیرو شده (DeepSeek-R1-Zero) است.
آروان-زیرو به دلیل برتری در تسکهای استدلالی بدون بهرهگیری از یک مجموعه آموزش SFT برچسبدار اهمیت پیدا میکند. فرایند آموزش آن به صورت مستقیم از یک مدل پایه پیشآموزش (pre-trained base model) به کمک آموزش مبتنی بر یادگیری تقویتی (بدون گام SFT) بهره میبرد. این مرحله ایه اندازهای خوب نتیجه میدهد که میتواند با مدل o1 رقابت کند.
این مسئله از آنجایی اهمیت مییابد که دادگان همواره سوخت قابلیتی مدلهای یادگیری ماشینی را تشکیل دادهاند. چگونه این مدل میتواند خود را از چنین تاریخچهای جدا سازد؟ این مورد به دو مسئله اشاره دارد:
مدلهای پایهای مدرن از یک آستانه کیفی و قابلیتی عبور کردهاند (این مدل پایه روی ۱۴.۸ تریلیون توکن با کیفیت بالا آموزش داده شده است)
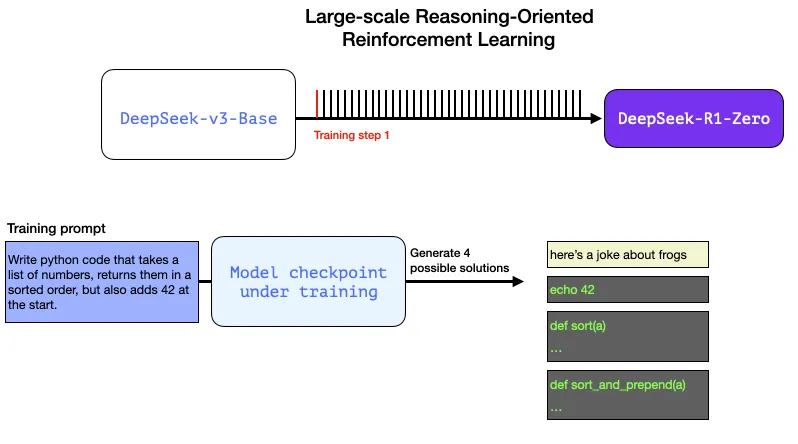
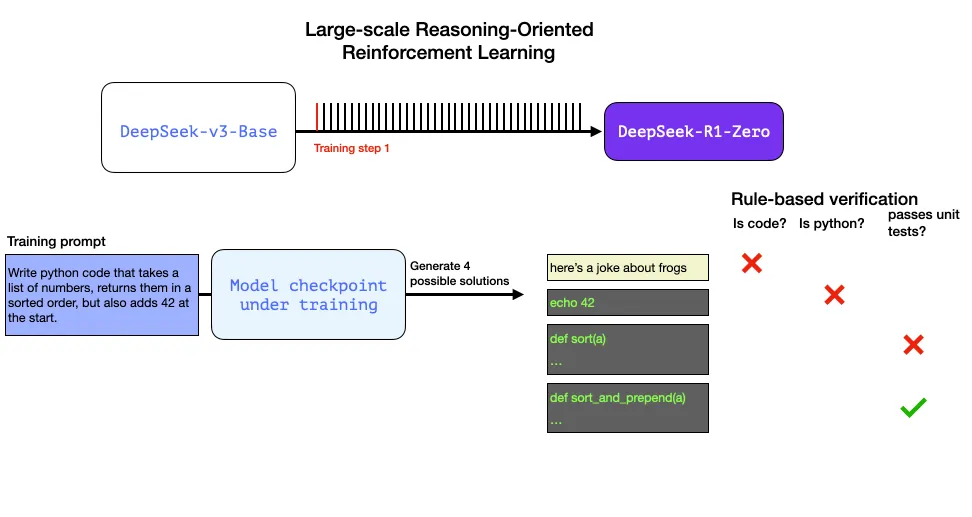
در مقابل گفتگوهای عام و یا درخواستهای مرتبط با نگارش (توصط کاربران به مدلهای زبانی)، مسائل استدلالی را راحتتر میتوان سنجید یا برچسبگذاری نمود. این مسئله میتواند یک پرامپت یا پرسش به عنوان گامی از آموزش یادگیری تقویتی باشد:
برنامهی پایتونی بنویسی که فهرستی (list) از اعداد را دریفات نماید، سپس مرتب شدهی آن را به عنوان خروجی بازگرداند، همچنین عدد ۴۲ را به عنوان اولین عدد در فهرست اضافه گرداند.
پرسشی نطیر آنچه مطرح شد را میتوان از طرق مختلفی سنجید. فرض کنید این درخواست به یک مدل آموزش دادهشده برای تکمیل داده شود:
یک نرمافزار لینتر (software linter) میتواند تکمیل شدن کد پایتون را مورد بررسی قرار دهد
میتوان کد پایتون را اجرا کرد تا از درست اجرا شدن آن باخبر شد
از مدلهای زبانی بزرگ دیگر میتوان برای آزمون واحد (unit tests) آن برای دریافت رفتار مورد انتظار بهره جست (بدون کمک کارشناسان متخصص در این حوزه)
میتوان حتی یک گام فراتر رفت و زمان اجرا را اندازهگیری کرد و فرایند آموزش را در راستای برگزیدن راهکارهای با بهرهوری بهتر سوق داد، حتی اگر تمامی آنها برنامههای پایتونی صحیحی برای حل مسئله باشند.
میتوان چنین مسئلهای را در حین آموزش به مدل عرضه داشت، و چندین راهحل محتمل را ایجاد کرد.
میتوان به صورت خودکار و بدون مداخلهی انسانی بررسی کرد که اولین پاسخ تکمیل شده کد نیست. دومی کد پایتون است اما مسئله مورد نظر را حل نمیکند. سومی یک راهحل محتمل است، اما به هنگام آزمون واحد به خطا بر میخورد، و چهارمی راهحل صحیح است.
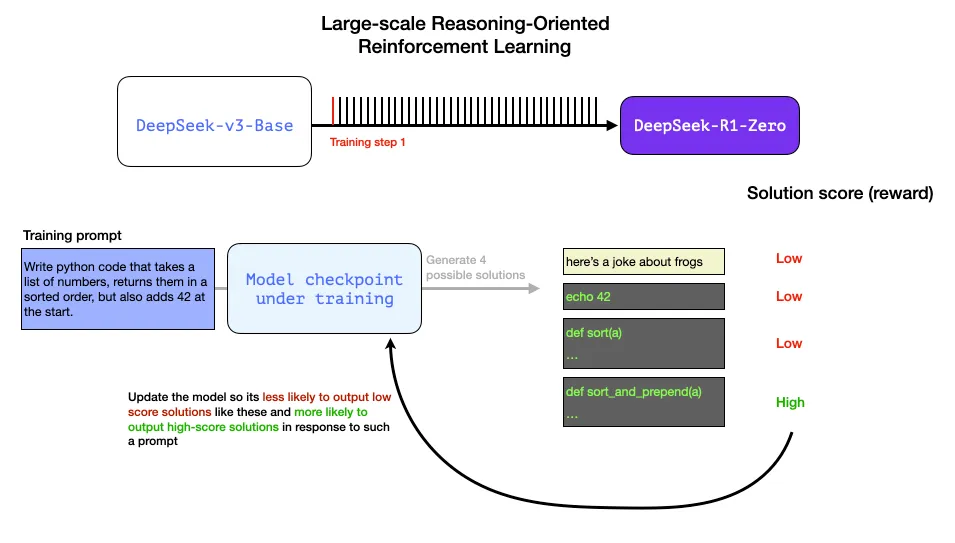
از تمامی این سیگنالها به صورت مستقیم میتوان برای بهبود مدل استفاده کرد. این مسئله در گامهای متعدد و در طول مراحل آموزش پشتسرهم انجام میشود.
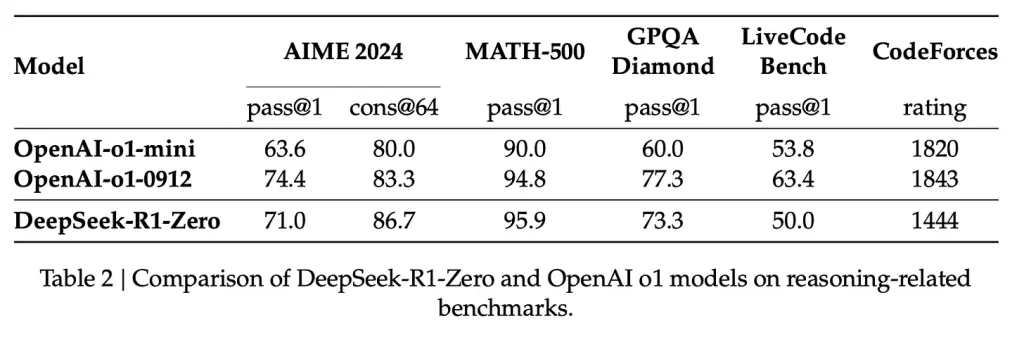
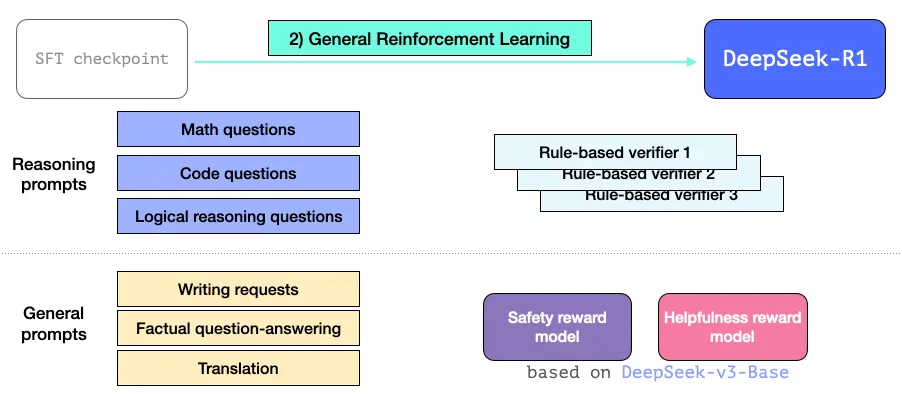
به کمک این سیگنالهای پاداش (reward signals) و بهروزرسانیهای مدل، در تسکهای مختلف به کمک فرایند یادگیری تقویتی مدل بهبود مییابد که میتوان آنرا در تصویر دوم مقاله مشاهده کرد.
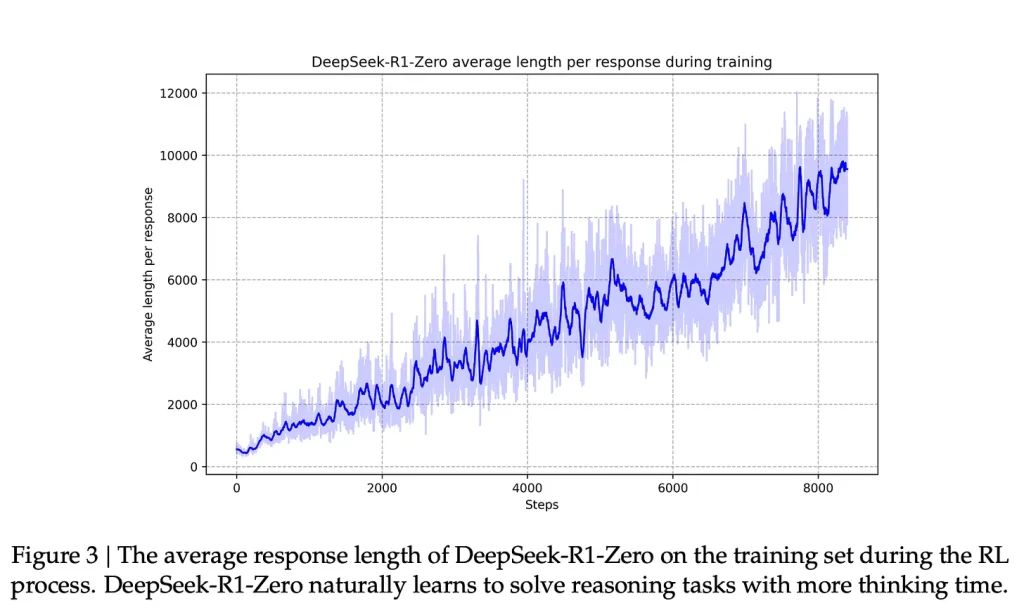
مرتبط با بهبود عملکرد مدل، طول پاسخهای ایجاد شده توسط مدل نیز به علت افزایش توکنهای تفکر مرتبط با فرایند مسئله افزایش مییابد.
با وجود مفید بودن این فرایند و کسب امتیازهای بالا در زمینه مسائل مرتبط با استدلال، مدل آروان-زیرو با مشکلات دیگری روبهرو میگردد که استفاده از آن را در زمینههای دیگر نامطلوب میکند.
باوجود توانمندی بالای مدل آروان-زیرو در مسائل مرتبط با استدلال و رفتارهای خودکار استدلالی قوی و غیرمنتظره، این مدل با مشکلات متعددی روبهرو میگردد. برای مثال چالشهایی نظیر ناخوانایی و ترکیب زبانها (language mixing).
مقصود آروان این است که یک مدل مفیدتر باشد. از همینروی به جای تکیه کامل بر فرایند یادگیری تقویتی، همانطور که قبلاً در این بخش به آن اشاره کردیم در دو مکان استفاده می شود:
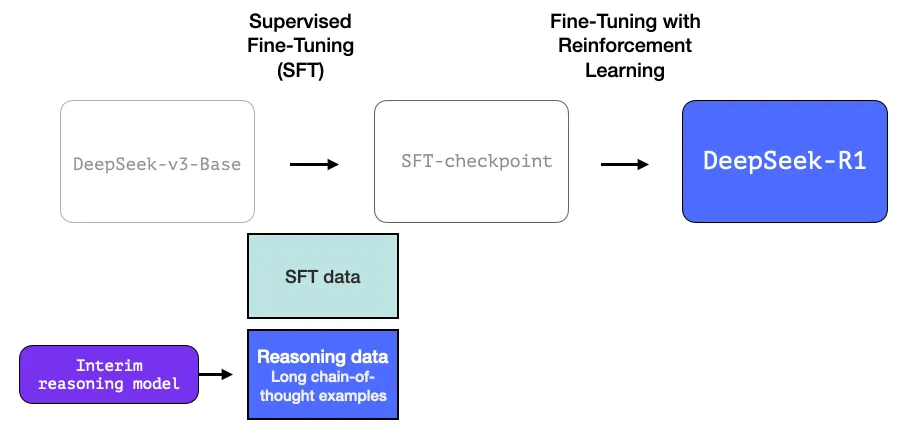
ایجاد یک مدل استدلالی موقت برای خلق نمونه دادههای SFT
آموزش مدل آروان برای بهبود مسائل استدلالی/غیراستدلالی (با بهرهگیری از سایر روشهای سنجش)
خلق دادههای SFT به کمک مدل استدلالی موقت
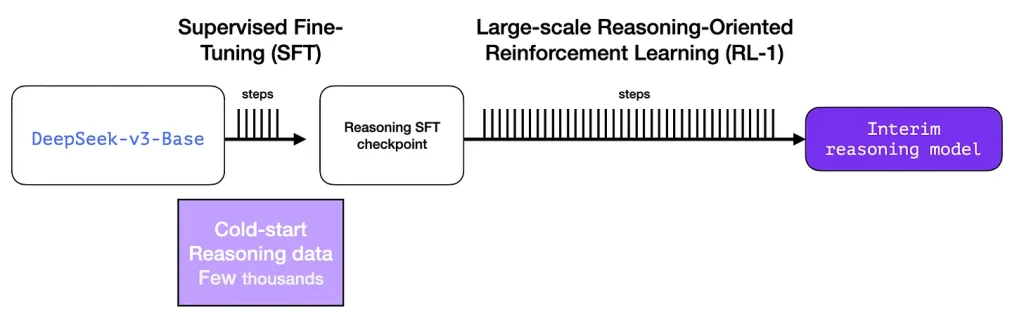
برای بهبود مدل استدلالی موقت، از یک گام آموزش تنظیم دقیق با نظارت بر روی مجموعه چندهزار مسئله استدلالی استفاده میگردد (که برخی از آنها به وسیله مدل آروان-زیرو ایجاد و فیلتر شدهاند). مقاله از این مرحله به عنوان شروع سرد (cold start) یاد میکند:
برخلاف آروان-زیرو، برای جلوگیری از ناپایداری فاز شروع سرد یادگیری تقویتی آموزش از مدل پایه، برای مدل دیپسیک-آروان مجموعهی کوچکی از دادگان long CoT برای تنظیم دقیق مدل آروان برای مجری اولیه یادگیری تقویتی آروان استخراج میگردد. برای جمعآوری چنین دادگانی، روشهای مختلفی بررسی شدهاند: با بهرهگیری از پارمپت چند-شات (few-shot) و یک long CoT به عنوان یک نمونه، به صورت مستقیم از مدل خواسته میشود تا پاسخهای باجزییات ایجاد کند به همراه بازتاب و سنجش، جمعآوردی خروجیهای دیپسیک-آروان زیرو در یک فرمت خوانا و پالایش نتایج به کمک حاشیهنویسان (annotators) انسانی.
صبر کنید، در صورتی که چنین دادهای را داشته باشیم، چرا باید از فرایند یادگیری تقویتی استفاده کرد؟ به خاطر مقیاس دادگان. این مجموعهداده میتواند از ۵۰۰۰ نمونه تشکیل شده باشد، اما برای آموزش آروان ۶۰۰.۰۰۰ نمونه نیاز است. این مدل موقت پلی بین گپ دادههای ساخته شده و دادگان باارزش میزند.
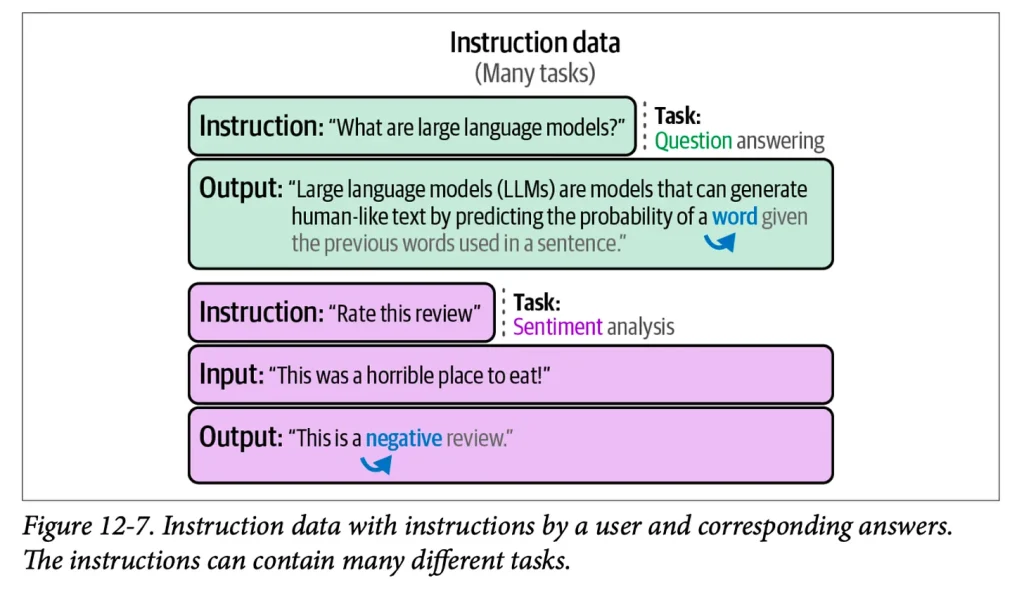
فرایند تنظیم دقیق بانظارت از ارائه نمونههای آموزشی در قالب پرامپت و تکمیل صحیح تشکیل شده است. تصویر فصل ۱۲ کتاب چند مورد از این فرایند را نمایش میدهد:
فاز آموزش یادگیری تقویتی عمومی
این فرایند آروان را قادر میسازد تا در تسکهای استدلالی و غیراستدلالی خوب عمل کند. این فرایند مشابه فرایند یادگیری تقویتی است که پیشتر مشاهده کردیم. اما از آنجایی که به تسکهای غیراستدلالی گسترش مییابد، از یک مدل کمک کننده و پاداش ایمنی (نه بر خلاف مدل های Llama) برای اعلان های مربوط به این برنامه ها استفاده می کند.
معماری
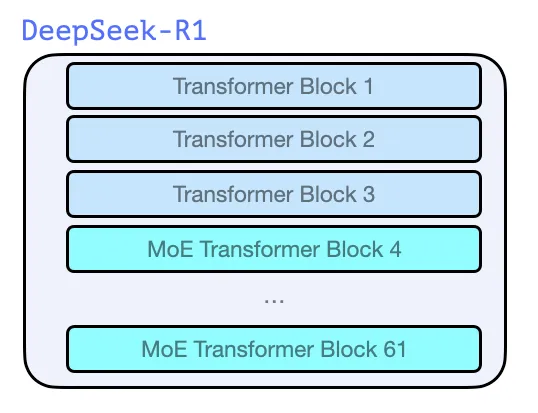
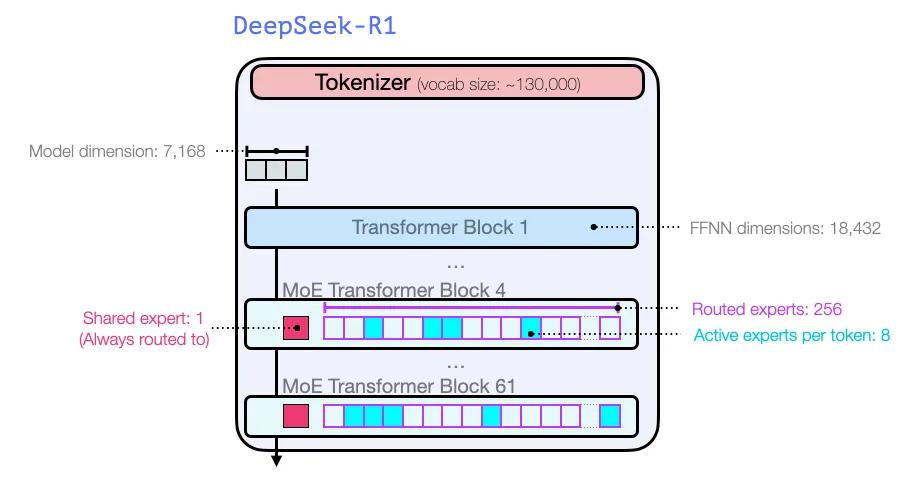
همانند مدلهای پیشین نشات گرفته از ظهور GPT2 و GPT 3، دیپسیک-آروان از یک استک ۶۱ بلاکهای دیکدر ترنسفورمر تشکیل شده است. سه تای اولی dense هستند اما بقیه از لایههای ترکیب متخصصان (mixture-of-experts) تشکیل شدهاند.
از نقطه نظر ابعاد و ابرپارامترها به شکل زیر است:
جزییات بیشتری از معماری در دو مقاله زیر قابل مشاهده است:
یادگیری در شبکههای عصبی ژرف (Deep Neural Networks) یکی از کلیدیترین جنبههای هوش مصنوعی است. این شبکهها به صورت گستردهای در بسیاری از کاربردهای عملی
مقدمه در دنیای پرشتاب امروز، دادهها به عنوان یکی از ارزشمندترین داراییهای بشر شناخته میشوند. با رشد نمایی حجم دادههای تولیدشده، اهمیت استفاده از این
یادگیری در شبکههای عصبی ژرف (Deep Neural Networks) یکی از کلیدیترین جنبههای هوش مصنوعی است. این شبکهها به صورت گستردهای در بسیاری از کاربردهای عملی
مقدمه ماشینهای خودران تنها وسایل نقلیهای با قابلیت حرکت خودکار نیستند؛ بلکه مجموعهای از سیستمهای هوشمند و پیچیدهاند که با استفاده از فناوریهای پیشرفته میتوانند